|
|
|
С.В. Петухов
«… истинная, единственная цель науки – ракрытие не механизма, а единства» | |
Анри Пуанкаре
|
История науки свидетельствует об особой важности поиска когнитивных (познавательных) форм представления феноменологических данных, то есть свернутых и удобных для анализа форм представления бесчисленных единиц информации о природе. Все развитие математического естествознания базируется во многом на нахождении таких форм. Классическим примером служит работа Кеплера, который, не проводя собственных астрономических наблюдений, сумел найти особую форму представления трудно обозримого множества астрономических данных о движении планет из гроссбухов Тихо Браге. Эта открытая им когнитивная форма, связанная с обобщающей идеей движения по эллипсам, позволила ему сформулировать законы движения планет относительно Солнца, вошедшие в историю под именем законов Кеплера. Во многом благодаря открытию этой когнитивной формы уже другой человек – Ньютон – сформулировал много лет спустя закон всемирного тяготения.
Сложная ситуация в современной молекулярной генетике недаром сравнивается специалистами мирового банка генетических данных Genbank с положением Кеплера: «Что дают нам миллионы нуклеотидов в последовательностях, известных на сегодняшний день? Мы находимся в положении Иоганна Кеплера, впервые приступающего к поиску закономерностей среди тех томов данных, которые всю жизнь собирал Тихо Браге. Мы знаем программу, запускающую клеточную механику, но мы почти ничего не знаем о том, как ее «прочитать». … мы все еще понимаем удручающе мало» [Математические методы для анализа последовательностей ДНК, 1999, с. 14]. В молекулярной генетике назрела задача поиска когнитивной формы представления трудно обозримого множества единиц экспериментальной информации.
Настоящая статья посвящена предлагаемой и развиваемой автором когнитивной форме представления данных о системе генетического кодирования, а также первым содержательным результатам ее использования. Эта форма представления основана на символьных и числовых матрицах генетических мультиплетов. Данные матрицы, условно называемые геноматрицами, составляют особые семейства, образуемые и исследуемые на основе классического матричного исчисления. Числовые геноматрицы порождаются из символьных геноматриц в результате замены символов генетических элементов их реальными количественными параметрами. Эта когнитивная форма представления уже привела к обнаружению новых феноменологических правил эволюции генетического кода, выявлению скрытых связей физико-химических параметров системы генетического кода с золотым сечением, обоснованию новых подходов (в частности, хронобиологических) к вопросам генетического кодирования, и пр. Оказывается, что загадочные наборы структур, реализованные природой в иерархической системе генетического кодирования, можно эвристическим образом сопоставлять с семействами математических матриц, составленных из элементов данных структур. Язык матричного исчисления, являющийся одним из основных во всем современном математическом естествознании и компьютерной информатике, неожиданно выступает в роли языка результативного представления системы генетического кодирования. Это открывает дополнительную возможность взаимного обогащения различных «матричных» областей науки, а также усиливает роль матричного исчисления в математическом естествознании в целом. В силу ограниченного объема статьи многие из полученных результатов данного направления приведены в ней фрагментарно в расчете на возможность знакомства с деталями по другим публикациям автора, приведенным в библиографии.
О полиплетной системе генетического кодирования. Молекулярная генетика открыла, что все живые организмы – от бактерии до кашалота и от червя до птицы и человека – имеют одни и те же основы генетического кодирования и в этом отношении неотличимы друг от друга. Другими словами, в науке произошло великое объединение живых организмов.
Соответственно информационная точка зрения на живые организмы стала особенно актуальной. В биологической литературе все чаще можно встретить утверждение, что живые организмы представляют собой тексты, начиная с молекулярного уровня их организации. С этой точки зрения организмы представляют собой информационные сущности. Они существуют потому, что получают наследственную информацию от своих предков и живут для того, чтобы передать свой информационный генетический пакет своим потомкам. При таком подходе все остальные физические и химические механизмы, представленные в живых организмах, можно трактовать как вспомогательные, способствующие реализации этой основной – информационной – задачи. Каждая физиологическая система – сенсорная, моторная и любая другая – закрепляется в биологической эволюции лишь в том случае, если она структурно согласована с генетической системой, может быть опосредованным образом закодирована в ней и передана по наследству последующим поколениям.
Основы языка наследственной информации поразительно просты. Для записи генетических посланий, кодирующих белки, в рибонуклеиновых кислотах любых организмов используется «алфавит», состоящий всего из четырех «букв» или азотистых оснований (рис. 1): аденин (А), цитозин (С), гуанин (G), урацил (U) (в ДНК вместо урацила используется родственный ему тимин (Т)). Именно строчная последовательность этих четырех букв (или моноплетов) на нитях нуклеиновых кислот содержит генетическую информацию для синтеза белков. Эти буквы образуют между собой комплементарные пары С-G и A-U, поскольку в молекулах наследственности стоят напротив друг друга и связаны соответственно тремя и двумя водородными связями.
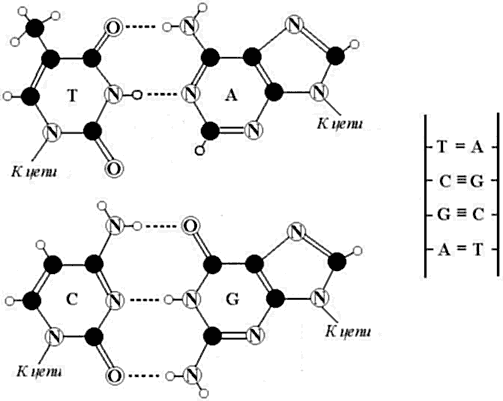
Рис. 1. Комплементарные пары четырех азотистых оснований в ДНК:
А — Т (аденин и тимин), С — G (цитозин и гуанин). Пунктиром даны водородные связи в этих парах. Черные кружки – атомы углерода, маленькие белые кружки – водорода, кружки с буквой N – азота, кружки с буквой O – кислорода.
Данный набор четырех букв обычно считается элементарным алфавитом генетического кода. Современной науке не известны причины того, почему алфавит генетического языка именно четырехбуквенный (а не из тридцати букв, например) и почему из миллиардов возможных химических соединений именно эти четыре азотистые основания выбраны в качестве элементов алфавита.
Генетическая информация, передаваемая молекулами наследственности (ДНК и РНК), определяет первичное строение белков живого организма. Каждый кодируемый белок представляет собой цепь из 20 видов аминокислот. В организме человека, например, примерно 40 000 видов белков, которые отличаются друг от друга очередностью и количеством аминокислот в них. Последовательность аминокислот в белковой цепи определяется последовательностью триплетов в молекуле наследственности. Триплетом называется блок из трех соседних азотистых оснований, расположенных вдоль нити ДНК (или РНК). Из четырехбуквенного алфавита можно составить всего 43 = 64 вида триплетов. Каждый из них имеет кодовое значение, кодируя ту или иную из 20 аминокислот или знаки начала и остановки белкового синтеза. Генетический код называется вырожденным, поскольку 64 триплета кодируют всего 20 аминокислот, и каждая аминокислота, как известно, может кодироваться разными — от одного до восьми – триплетами. Если произвольная белковая цепь содержит n аминокислот, то соответствующая ему последовательность (секвенции) азотистых оснований в молекуле ДНК содержит 3n азотистых оснований или, другими словами, задается 3n-плетом. Белковые цепи обычно содержат сотни аминокислот и соответственно задаются весьма длинными полиплетами. Вся система генетического кода белков является полиплетной – от четырех моноплетов генетического алфавита и 64 триплетов до полиплетов из многих тысяч элементов. Эта система может быть представлена как состоящая из семейств полиплетов одинаковой длины.
Матричное представление генетических полиплетов. Информация в компьютере обычно хранится в виде матриц. Автор предложил представлять систему четырех букв генетического алфавита в форме символьной квадратной матрицы второго порядка Р (Рис. 2). И, кроме того, рассматривать всю трудно обозримую систему семейств одинаковых по длине генетических полиплетов в виде соответствующего семейства матриц P(n), представляющих собой тензорные (кронекеровы) степени данной матрицы Р (скобки при показателе степени означают, что возведение в степень n понимается в смысле тензорного умножения матриц, символом которого является знак Д). Для терминологического обозначения предложено называть эти взаимосвязанные матрицы геноматрицами, поскольку они состоят из генетических полиплетов. Данное семейство геноматриц Р(n) при достаточно большом «n» унифицированным образом представляет всю систему генетических кодовых полиплетов, как кодирующих белки всех живых организмов, так и имеющих иное кодовое содержание: моноплеты генетического алфавита и триплеты, кодирующие не белки, а аминокислоты.
В каждом из четырех квадрантов геноматрицы Р(n) собраны все n-плеты, начинающиеся с одной из четырех букв С, А, U, G. Если не обращать внимания на эту первую букву в n-плетах квадранта, то легко видеть, что квадрант матрицы Р(n) полностью воспроизводит матрицу Р(n-1) предыдущего поколения (это обусловлено свойствами тензорного возведения матрицы в степень). Если процесс образования в этом семействе очередных геноматриц Р(n) с ростом «n» условно назвать эволюционным порождением очередного поколения геноматриц, то геноматрица каждого нового поколения в силу описанной особенности содержит в себе в скрытом виде информацию о всех предыдущих поколениях (геноматрицы с «памятью поколений»). Самая большая геноматрица Р(n), n-плеты которой кодируют самый длинный из белков, называется архматрицей. Поскольку она содержит в себе информацию обо всех геноматрицах с более короткими кодовыми полиплетами, то формально задача исследования всей системы генетических полиплетов сводится к изучению архматрицы.
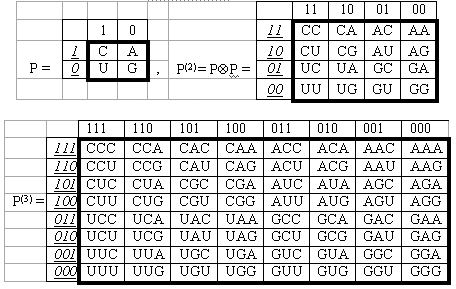
Рис. 2. Простейшие представители семейства геноматриц Р(n) для случаев n = 1, 2, 3 /Петухов, 2001/.
Эти геноматрицы возникли в ходе авторского исследования набора структурных признаков у четырех азотистых оснований А, С, G, U. Данное исследование показало, что этот набор четырех биохимических структур является носителем трех пар оппозиционных признаков, с учетом которых четырехбуквенный генетический алфавит содержит три бинарных субалфавита [Петухов, 2001; Petoukhov, 1999, 2001a]. Для данной статьи существенно лишь отметить, что из четырех букв кода две буквы С и U являются пиримидинами, а две другие буквы А и G – пуринами. Поэтому можно на объективной основе ввести бинарную систему обозначений (первый бинарный субалфавит), в которой пиримидины С и U характеризуются символом 1, а пурины А и G – символом 0. По другой паре оппозиционных признаков (наличию или отсутствию свойства аминомутируемости) — эквивалентными оказываются другие пары букв, что позволяет ввести другую бинарную систему обозначений (второй бинарный субалфавит): эквивалентные по наличию данного свойства буквы С и А обозначаются символом 1, а другая пара букв, лишенная этого свойства, — символом 0 (для отличия данных двух бинарных систем бинарные символы второй системы наклонены и подчеркнуты). В матрицах на Рис. 2 указаны бинарные номера всех столбцов и строк. Эти номера образуются автоматически при чтении полиплетов каждого столбца с точки зрения первого бинарного субалфавита, а полиплетов каждой строки – с точки зрения второго бинарного субалфавита. Например, триплет СAU в первом субалфавите имеет бинарное побуквенное обозначение 101 (совпадает с бинарными обозначениями всех триплетов его столбца, а потому используется как номер данного столбца), а во втором субалфавите – бинарное обозначение 110 (совпадает с бинарными обозначениями всех триплетов его строки, а потому используется как ее номер). В силу такой эквивалентности триплетов по строкам и столбцам матрицы с точки зрения двух бинарных субалфавитов данные геноматрицы называются также бипериодическими.
Формально построенная матрица Р(3) содержит все 64 триплета. Каждый из ее столбцов представляет собой один из восьми классических октетов Виттмана [Wittmann, 1961], отражающих реальные биохимические свойства элементов кода. Это является первым косвенным подтверждением состоятельности данного матричного подхода, вскрывающего упорядоченность внутри генетической системы.
Числовые геноматрицы. При замене в символьных матрицах Р(n) каждого символа азотистых оснований на те или иные их количественные параметры получаются соответствующие числовые геноматрицы. Конкретным примером служат мультипликативные матрицы водородных связей азотистых оснований кода. Комплементарные водородные связи букв кода давно подозреваются на особую информационную значимость. Речь идет о двух и трех водородных связях (по которым C=G=3, A=U=2), соединяющих комплементарные пары азотистых оснований в молекулах наследственности. Заменим каждый полиплет во всех матрицах P(n) произведением чисел водородных связей его азотистых оснований. При этом, например, триплет СGА в октетной матрице P(3) заменяется на произведение 3х3х2=18. В результате получаем мультипликативные числовые невырожденные матрицы Рмульт(n). В частности, получаем октетную матрицу Рмульт(3) (Рис.3):
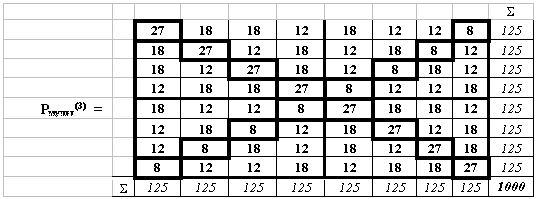
Рис. 3. Мультипликативная матрица Рмульт(3), которая содержит произведения чисел водородных связей для триплетов (C=G=3, A=U=2). Правый столбец показывает сумму чисел в каждой строке. Нижняя строка показывает сумму чисел в каждом столбце. Жирными рамками обведены диагональные ячейки матрицы.
Так возникающие числовые матрицы Рмульт(n) симметричны относительно обеих диагоналей, а потому названы бисимметрическими. Они имеют интересные свойства. Так, в любой из матриц Рмульт(n) сумма чисел в каждой ее строке и каждом ее столбце равны 5n, а общая сумма чисел в матрице равна 10n. Например, в матрице Рмульт(3) суммы в строке и столбце равны 125, а общая сумма чисел равна 1000. Детерминант Рмульт(3) равен 512.
Золотое сечение и золотые геноматрицы. Автор с удивлением обнаружил, что эти бисимметрические геноматрицы Р(n) связаны с золотым сечением, которое, по крайней мере, со времен Возрождения (Леонардо да Винчи, Иоганн Кеплер и др.). служит в математике символом самовоспроизведения. Десятки авторов в разных странах публикуют статьи о проявлении золотого сечения в различных физиологических системах и процессах: сердечно-сосудистых, дыхательных, локомоторных, психофизиологических и пр. В свете этого золотое сечение выступает кандидатом на роль одного из базовых элементов в феномене наследуемой сопряженности физиологических подсистем, обеспечивающей единство организма.
Выявленная скрытая связь между золотым сечением φ = (1+50.5)/2 = 1, 618… и основными параметрами генетического кода заключена в том, что каждая из мультипликативных геноматриц Рмульт(n) представляет собой вторую степень соответствующей «золотой» матрицы Фмульт(n): Рмульт(n) = (Фмульт(n))2. Для примера рассмотрим корень квадратный из матрицы Рмульт(3) (Рис. 4). Каждый из 64 элементов этой бисимметрической матрицы представляют собой именно золотое сечение φ, взятое в одной из четырех степеней ± 1 и ± 3, образующих инверсионные пары (типа инь-янь): φ+1 и φ-1; φ+3 и φ-3. Подобные матрицы, все элементы которых представляют собой золотые сечения в той или иной целой степени, автор называет «золотыми». Обнаружен простой алгоритм выписывания всех элементов золотой матрицы Фмульт(n), квадрат которой равен матрице Рмульт(n), без проведения перемножения матриц. Он заключается в замене каждого полиплета в исходной символьной матрице Р(n) (см. Рис. 2) произведением следующих числовых значений для его букв: С = G = φ, A = U = φ-1. Например, триплет СGА в октетной матрице P(3) заменяется на произведение φ х φ х φ-1 = φ.
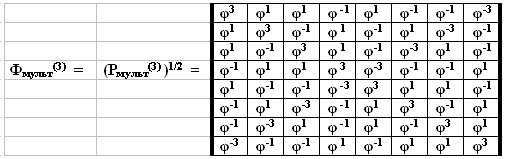
Рис. 4. Октетная золотая геноматрица Φмульт (3) = (Pмульт (3))1/2, в которой через φ обозначено золотое сечение.
Все матрицы (Рмульт(n))1/2 являются золотыми. Образно говоря, геноматрицы имеют скрытую подложку из золотых матриц. Например:

Рис. 5. Начало семейства золотых геноматриц (Pмульт (n))1/2 = Φмульт (n), в которых через
φ обозначено золотое сечение.
Обнаружение связи золотого сечения с параметрами генетического кода и геноматрицами позволило автору предложить новое – матрично-генетическое – определение золотого сечения: золотое сечение и его обратная величина (φ и φ-1) представляют собой единственные матричные элементы бисимметрической матрицы Φ, являющейся корнем квадратным из такой бисимметрической числовой матрицы Pмульт второго порядка, элементами которой являются генетические числа водородных связей (C=G=3, A=U=2) и которая имеет положительный детерминант. Это определение не использует элементов классических определений золотого сечения: отрезков прямой, квадратного уравнения, предельного отношения в специальных числовых рядах. Кроме того, оно носит бинарный характер, определяя сразу системную пару взаимообратных величин φ и φ-1 (в разных литературных источниках золотым сечением называют или величину φ или обратную величину φ-1).
Имеется огромный литературный материал о применении золотого сечения для анализа и моделирования множества природных явлений и систем – от астрономии до биологии и физики элементарных частиц. Выдвинутое положение о матричном определении и матричной сущности золотого сечения дает эвристическую возможность рассмотреть весь этот материал на предмет его содержательной интерпретации с принципиально новой – матричной — точки зрения. Автор полагает, что многие реализации золотого сечения в живой и неживой природе связаны именно с матричной сущностью и матричным представлением золотого сечения. Математика золотых матриц – новая математическая веточка, изучающая, в частности, рекуррентные соотношения между рядами золотых матриц, а также моделирование с их помощью природных систем и процессов [Petoukhov, 2001a].
Свойства бисимметрических генетических матриц. Золотые и другие бисимметрические матрицы проявляют неожиданные инвариантно-групповые свойства, связанные с умножением матриц [Petoukhov, 2001a, 2003; Петухов, 2004]. Поясним их на примере октетной золотой матрицы (Рмульт(3))1/2 = Φмульт (3). Эта матрица содержит только четыре числа: φ+1 иφ-1; φ+3 иφ-3, расположение которых образует характерную мозаику. Каждое из чисел φ+3 иφ-3 занимает все ячейки соответствующей диагонали матрицы, а вместе совокупность ячеек этих чисел образует фигуру креста. Ячейки, занятые числом φ-1, образуют мозаику, напоминающую символ «69» (Рис. 6). Ячейки, занятые обратным числом φ+1, образуют мозаику зеркального изображения этого символа «69».
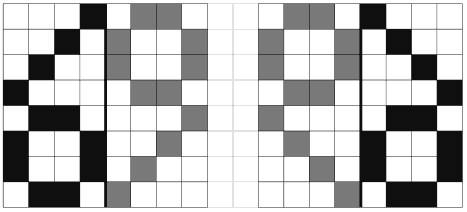
Рис. 6. Мозаика ячеек с числом φ-1 (слева, зачернено) и мозаика ячеек с числом φ+1 (справа)
Вообще говоря, при возведении в квадрат или другую степень произвольной октетной матрицы, содержащей четыре вида повторяющихся чисел, в общем случае получается матрица, содержащая много больше видов чисел (вплоть до 64 видов). Но золотая матрица Фмульт(3) при возведении в любую степень демонстрирует свойство мозаико-инвариантности. Оно заключается в том, что новая матрица также содержит только четыре вида чисел, причем с тем же самым мозаичным расположением. Например, матрица (Фмульт (3))2 = Рмульт(3) содержит четыре вида чисел 8, 12, 18 и 27 с той же мозаикой их расположения. В силу этого свойства из таких матриц можно, например, образовывать многочлены, которые сами будут матрицами данного типа. Это свойство мозаико-инвариантности выполняется для всех бисимметрических матриц и оно не зависит от величины самих чисел, а только от характера их расположения в матрице. Оно выполняется не только для операций возведения матрицы в степень, но и для перемножения бисимметрических матриц рассматриваемого типа с наборами чисел, отличающихся по величине (Рис. 7).

Рис. 7. Иллюстрация свойства мозаико-инвариантности при перемножении матриц
рассматриваемого типа (пояснение в тексте)
При этом каждый из четырех элементов в данных матрицах, очевидно, может быть не только вещественным числом, но также комплексным числом, произвольной функцией от времени, блочной матрицей и т.д. Другими словами, свойство мозаико-инвариантности рассматриваемого семейства бисимметрических генетических матриц не зависит от вида или поведения индивидуального члена набора, а носит кооперативный характер. Оно дает пример системы, целостная форма которой не зависит от поведения отдельных ее элементов. Это напоминает ситуации, распространенные в биологии, когда, например, целостная форма эмбриона мало зависит от отдельных клеток в составляющем его клеточном ансамбле.
А каковы числовые мозаики в последовательности рассматриваемых числовых матриц, например, матриц Фмульт(n) и как они взаимосвязаны?
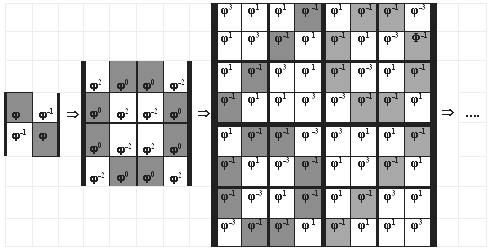
Рис. 8. Примеры глобальных мозаик в последовательности матриц Фмульт(n)
Каждая матрица Фмульт(n) при n = 2, 3, 4, … имеет глобальные числовые мозаики, проявляющиеся при рассмотрении матрицы в целом, и локальные числовые мозаики, проявляющиеся при рассмотрении только отдельных квадрантов и субквадрантов матрицы. Бесконечное семейство таких бисимметрических матриц образует «цепь поколений с наследованием мозаик». При этом по ходу данной цепи матриц глобальные числовые мозаики предыдущего звена становятся локальными мозаиками в очередных звеньях, а картина глобальных мозаик все усложняется, образуя интересные и, вероятно, физиологически значимые формы [Petoukhov, 2003].
Эта цепь матриц допускает много интересных модификаций. Например, у матриц цепи могут переставляться их половины («кроссинговер» матриц) с образованием новой бисимметрической матрицы с новой инвариантной мозаикой и новыми свойствами. Так, перестановка левой и правой половин октетной матрицы Фмульт(3) дает матрицу с мозаикой по форме символа «96». Эта матрица при возведении в степень дает пульсирующую бинарную последовательность: при возведении в четную целую степень она порождает матрицу с мозаикой «69», а при возведении в нечетную – матрицу с мозаикой «96».
Отметим аналогию между бисимметрическими геноматрицами второго порядка, например, Φмульт и известными матрицами гиперболических поворотов, которые также бисимметричны: [sh x ch x; ch x sh x] ((здесь и далее матрицы записаны в строчной форме, известной, например, по программе Matlab). Данная аналогия позволяет интерпретировать бисимметрические геноматрицы в связи с гиперболическими поворотами, имеющими приложения в физике и математике [Петухов, 2004в]. Речь идет, прежде всего, об их приложениях в специальной теории относительности и релятивистском солитонном уравнении синус-Гордона, ранее выдвинутом автором в связи с общебиологическими феноменами надмолекулярных солитонов на роль фундаментального солитонного уравнения для живой материи [Петухов, 1999]. Эта аналогия представляет геноматрицы высоких порядков в виде соответствующих тензорных степеней матрицы (2х2) гиперболического поворота. Она позволила получить выражение мнимой единицы i = (-1)1/2 через золотое сечение φ, а также через число π:
i = Arch(1/(2* φ)) / arccos (1/(2* φ)); i = Arch[cos(0,4* π)] / (0,4* π), (1)
где Arch и arcсos – гиперболический и тригонометрический арккосинусы. Отметим также, что матрица гиперболического поворота может быть записана в терминах «золотых гипер- болических функций» [Стахов, 2003, с. 255], которые этим связываются с геноматрицами.
О других формах записи базовой геноматрицы. Предпринятое автором представление системы четырех элементов генетического алфавита в виде базовой матрицы Р (Рис. 2) и использование вещественных чисел при переходе к числовым матрицам, характеризующим систему количественных параметров данных элементов, является волевым актом. Формально с тем же правом можно рассматривать базовую матрицу генетического алфавита с использованием иных типов чисел, например, комплексных. В свете этого автором рассмотрен ряд альтернативных форм записи базовой матрицы генетического алфавита, прежде всего, эрмитова комплексная форма записи, напоминающая известную в квантовой механике матрицу Паули (Рис. 9). При переходе к числовым представлениям этих матриц Pi (где i – мнимая единица) через числа водородных связей С=G=3, A=U=2 получаем комплексные числовые матрицы (Pi мульт)(n), обладающие многими из свойств вышеописанных числовых матриц (Pмульт)(n). В том числе они также имеют квадратичную связь с золотыми матрицами комплексного типа, примеры которых приведены на Рис. 9. Данные комплексные числовые геноматрицы являются квази-бисимметрическими, поскольку мнимые числа, расположенные симметрично относительно главной диагонали, противоположны по знаку, как и в исходной матрице (Рi мульт). Это отражает эрмитовость матриц (Pi мульт)(n).

Рис. 9. Пример комплексной формы записи базовой геноматрицы Pi. При ее числовом представлении с С=G=3, A=U=2 образуется матрица (Pi мульт), которая является квадратом соответствующей комплексной золотой матрицы (Φi мульт). Здесь i – мнимая единица. Слева вверху – матрица Паули.
Комплексная форма геноматриц представляется особенно интересной в связи с возможностью формальной интерпретации числовых геноматриц (при их соответствующей нормировке) как матриц плотности статистической квантовой механики (см. ниже).
Добавим, что в биологической морфологии исключительно широко реализуются спиральные формы. По этой причине спирали давно называются «линиями жизни» [Cook, 1914]. Один из вариантов квази-бисимметрической золотой матрицы, легко связываемый с базовой геноматрицей Р и сохраняющий многие ее математические свойства, эквивалентен матрице преобразования вращения в плоскости: 1/3*[j j -1; -j -1 j ] = [cosa sina; -sina cosa ]. Поэтому итеративное применение данной и других золотых матриц может использоваться для моделирования спиралей. Интерпретация таких геноматриц как матриц поворота в случаях углов 720 и 360 симметрии вращения у правильных пятиугольника (пентаграммы) и десятиугольника позволяет получить следующие формулы выражения числа π через золотое сечение j:
π = (10/3) * asin(j /2); π = 10 * arcsin[1/(2*j)] (2)
Интересно, что через золотое сечение точным образом выражаются числа π, мнимая единица i, основание натурального логарифма е, все целые положительные числа (однозначно представимые в фибоначчиевой системы счисления). Это позволяет рассматривать золотое сечение как «проточисло», которое может сыграть важную роль в концепции, связанной с именами Д. Гильберта, Б. Рассела и др., о возможном в будущем теоретическом вычислении фундаментальных физических констант (типа постоянной тонкой структуры) через математические «проточисла», а не путем установления их приближенных значений в физических экспериментах (см. обзор в [Аракелян, 1981]). Описанное выше новое определение золотого сечения через геноматрицы, связанные с матрицами гиперболического и тригонометрического поворота, также может оказаться полезным в реализации этой концепции, как и сами эти матрицы.
Разнообразие вариантов числовых представлений геноматриц перекликается с наличием множества параллельных каналов информации у организма и его способностью полифункционального использования своих структур.
Симметрия аминокислот в геноматрице триплетов. Как размещаются 20 аминокислот в матрице Р(3), содержащей все 64 триплета? Нет никаких исходных оснований надеяться на их симметричное расположение в ней. Матрица Р(3) триплетов строится на формальной основе возведения простейшей матрицы Р из четырех букв кода в третью тензорную степень без какого-либо упоминания об аминокислотах и без учета кодовой роли триплетов. Кроме того, между триплетными последовательностями ДНК и местом сборки соответствующей цепи аминокислот лежит целая биохимическая пропасть из большого числа промежуточных биохимических агентов и процессов, кооперативная деятельность которых сама по себе представляет научную проблему, далекую от ясности. Если же вдруг окажется, что в полученную формальным способом матрицу 64 триплетов множество 20 аминокислот впишется упорядоченным, симметрическим образом, то этот феноменологический факт будет сильным аргументов в пользу адекватности матричного представления системы генетического кодирования.
Оказывается, что именно закономерное, симметрическое расположение категорий аминокислот с различной кодовой вырожденностью реализуется в данной матрице Р(3) [Петухов, 2001]. На Рис. 10 представлено распределение аминокислот и стоп-кодонов по ячейкам триплетов для случая генетического кода митохондрий человека и позвоночных, который в литературе называется наиболее древним и идеальным.
В матрице Р(3) каждый ее субквадрант размером (2х2) содержит подсемейство всех тех четырех триплетов, которые эквивалентны друг другу по своим двум первым буквам. Будем называть такие четверки подсемействами NN-триплетов. Все множество 16 подсемейств NN-триплетов в рассматриваемом случае поделено природой на два подмножества по 8 подсемейств в каждом. Первое подмножество, выделенное черным цветом на Рис. 10, содержит подсемейства таких NN-триплетов, кодовое значение которых не зависит от третьей буквы триплета. В силу этого все четыре триплета подсемейства кодируют одну и ту же аминокислоту. Второе подмножество содержит подсемейства NN-триплетов, кодовое значение которых зависит от третьей буквы, а потому в каждом подсемействе некоторые из четырех триплетов кодируют одну аминокислоту, а другие – другую (или стоп-сигнал белкового синтеза).
Расположение этих «черных» и «белых» подсемейств NN-триплетов в матрице P(3) носит выражено симметричный характер. Так, левая и правая половины матрицы зеркально-антисимметричны по своей черно-белой мозаике: любая пара ячеек, расположенных зеркально симметрично в левой и правой половинах матрицы, имеют противоположный цвет относительно друг друга. Пары квадрантов, расположенные вдоль любой диагонали, эквивалентны друг другу по своей мозаике. Четыре пары соседних строк 1-2, 3-4, 5-6, 7-8 эквивалентны между собой по расположению в них идентичных аминокислот.
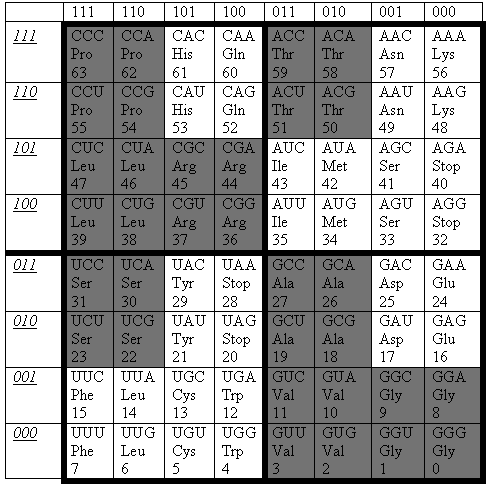
Рис. 10. Расположение 20 аминокислот в геноматрице Р(3) для генетического кода митохондрий человека и позвоночных /Петухов, 2001, с. 99 и 106/. 20 аминокислот обозначены их классическими сокращениями типа Pro, His, Gln и пр. Стоп-кодоны обозначены как «stop». Те субквадранты (2х2) таблицы, которые содержат подсемейства NN-триплетов, все четыре триплета которых кодируют одну и ту же аминокислоту не зависимо от буквы на их третьей позиции, закрашены черным цветом в отличие от субквадрантов, подсемейства NN-триплетов которых не имеют этого свойства. Числами от 0 до 63 указаны естественные порядковые номера триплетов.
Из всего множества 20 аминокислот 8 аминокислот принадлежат черным квадрантам матрицы Р(3), а остальные 12 аминокислот фигурируют в ее белых квадрантах. Симметрическое распределение множества 20 аминокислот в матрице Р(3) позволило автору обнаружить скрытую регулярность в эволюционных феноменах вырожденности генетических кодов и сформулировать соответствующее феноменологическое правило об эволюционных инвариантах в данном множестве, что изложено в следующем параграфе.
Правила вырожденности и две ветви эволюции внутри генетического кода. Начиная с уровня биологического соответствия множества 64 триплетов множеству 20 аминокислот в природе начинает наблюдаться значительное эволюционное разнообразие кодов. На сегодня известно 17 генетических кодов, исходные данные о которых взяты автором на общедоступном сайте авторитетного «National Center for Biotechnology Information (США)»: http://www.ncbi.nlm.nih.gov/Taxonomy/Utils/wprintgc.cgi. В каждом генетическом коде любая из 20 аминокислот кодируется определенным числом триплетов. Это число кодирующих ее триплетов будем называть числом вырожденности аминокислоты в данном коде. Разные генетические коды имеют несколько разные совокупности своих чисел вырожденности для унифицированного набора из 20 аминокислот, причем у всех известных кодов числа вырожденности лежат в диапазоне их значений от 1 до 8. Например, аминокислота Thr в одном коде кодируется четырьмя триплетами, т.е. имеет в этом коде число вырожденности 4, а в другом коде она почему-то кодируется 8 триплетами и т.д.
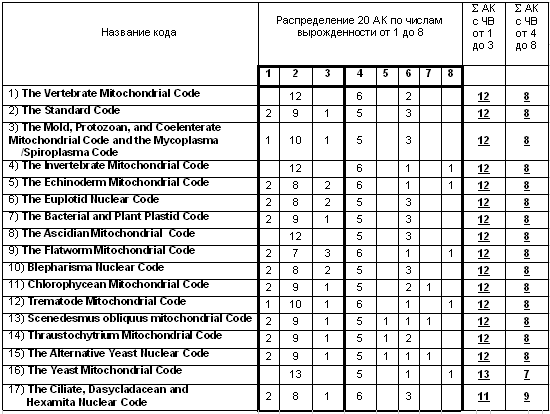
Рис. 11. Феномен разделения в генетических кодах множества 20 аминокислот на два типовых подмножества – высоковырожденных и низковырожденных — аминокислот (из /Петухов, 2001/). В двух правых столбцах показаны количества S низковырожденных аминокислот (с числом вырожденности от 1 до 3) и высоковырожденных аминокислот (с числом вырожденности от 4 до 8). АК означает аминокислоты, ЧВ – число вырожденности аминокислоты.
Множество вариантов генетических кодов, отличающихся по своей вырожденности, отражает особенности биологической эволюции на самых базовых уровнях. В силу этого представляется, что сравнительный анализ данных кодов способен дать важную информацию о сущности биологических организмов и жизни в целом. Такой сравнительный анализ, предпринятый автором, выявил существование определенных эволюционных правил. Первое знакомство с набором чисел вырожденности аминокислот в 17 известных кодах производит впечатление нерегулярности этого набора, отсутствия в нем содержательной закономерности. Однако, это впечатление исчезает, если только предпринять разделение всех 20 аминокислот на две типовые категории аминокислот — низковырожденных (с числами вырожденности от 1 до 3) и высоковырожденных (с числами вырожденности от 4 до 8).
Представленные в таблице на Рис. 11 данные позволили автору сформулировать следующее феноменологическое правило № 1 [Петухов, 2004; Petoukhov, 2001]:
- в генетических кодах множество 20 аминокислот содержит два оппозиционных подмножества: одно – из 12 низковырожденных аминокислот (с числами вырожденности от 1 до 3), и второе – из 8 высоковырожденных аминокислот (с числами вырожденности от 4 до 8).
Существует малое исключение из этого правила: два кода из семнадцати имеют соотношение количества низковырожденных и высоковырожденных аминокислот, равное 11:9 и 13:7. Эти нестандартные отношения являются минимально возможными отклонениями от канонического отношения 12:8 (для двух чисел, дающих в сумме 20) и окружают его с обеих сторон на числовой оси, подчеркивая его центральную роль. Правило выполняется особо строго для автотрофных организмов, которые добывают углерод для своего тела благодаря механизмам фотосинтеза.
Отметим, что с разделением 20 аминокислот на две категории из 12 и 8 аминокислот мы уже встречались в конце предыдущего параграфа в связи с черными и белыми подсемействами NN-триплетов в матрице P(3). Именно «черные» подсемейства NN-триплетов кодируют в этой матрице (Рис. 10) восемь высоковырожденных аминокислот Ala, Arg, Gly, Leu, Pro, Ser, Thr, Val, а остальные двенадцать аминокислот Asn, Asp, Cys, Gln, Glu, His, Ile, Lys, Met, Phe, Trp, Tyr кодируются NN-триплетами из «белых» подсемейств. Эти конкретные наборы из 8 и 12 аминокислот двух категорий вырожденности будем называть каноническими.
Как оказывается, в природе достаточно строго реализуется еще одно Правило № 2:
- если какой-то триплет кодирует разные аминокислоты в разных генетических кодах, то все эти аминокислоты относятся к одному и тому же каноническому набору аминокислот (высокой или низкой вырожденности). Другими словами, в ходе биологической эволюции генетических кодов триплетам, кодирующим аминокислоты из одного канонического набора вырожденности, практически запрещено переходить в группу триплетов, кодирующих аминокислоты другого канонического набора.
Единственным исключением из этого правила является триплет UAG, который в разных кодах может кодировать аминокислоты Leu или Gln, относящиеся к разным категориям. В этом правиле № 2 не фигурируют стоп-кодоны, а потому оно не относится к тем эволюционным случаям, когда триплеты, кодировавшие в коде на Рис. 10 стоп-кодоны (или аминокислоты), начинают кодировать аминокислоты (или стоп-кодоны).
Описанные эволюционные факты существования двух категорий аминокислот, отличающихся своей вырожденностью и почти полной обособленностью по наборам кодирующих их триплетов на всем множестве 17 генетических кодов, свидетельствуют в пользу следующего. Существуют две самостоятельные ветви эволюции генетического кода у миллионов видов живых организмов: одна — для канонического набора высоковырожденных аминокислот, а вторая – для канонического набора низковырожденных аминокислот. Эти две ветви эволюции внутри единой кодовой системы можно образно сравнить, например, с параллельной эволюцией женского и мужского организмов в рамках одного биологического вида, или с эволюцией гласных и согласных звуков в языке.
Одновременно обнаруживается, что вместо единого множества 20 аминокислот природа реализует объединение двух весьма разных подмножеств из 8 и 12 аминокислот (по типу инь-янь категорий). Отметим еще ряд математических особенностей природной системы чисел вырожденности у аминокислот.
Примечание 1: наименьшим общим делимым для чисел 8 и 12 является число 24.
Примечание 2: основные числа вырожденности аминокислот во всех кодах – 1, 2, 3, 4, 6, 8 — являются делителями числа 24 (в четырех кодах есть по одной аминокислоте, у которой число вырожденности равно 5 или 7; встречаемость каждого из этих экстраординарных чисел вырожденности в 17 кодах составляет всего 0,88 %).
Предсказание: вероятно существование неизвестного генетического кода, у которого одна из аминокислот имеет число вырожденности 12 (оно также является делителем 24) [Petoukhov, 2001b].
В связи с фактами, отмеченными в этих двух примечаниях, число 24 может рассматриваться как скрытая константа согласования чисел вырожденности в генетических кодах. Число 24 давно известно в биологии в связи с хрономедициной, имеющей успешную тысячелетнюю историю и говорящей о том, что в течение суток системы организма претерпевают закономерные смены физиологической активности и пассивности в рамках определенных интервалов времени, связанных с делением суток на 24 равные части. Положения восточной хрономедицины, тесно сопряженные с символьными системами древнекитайской «Книги перемен» и суточным циклом «день-ночь» поступления солнечной энергии на поверхность земли, являются составной частью акупунктуры, тибетской диагностики по пульсу, учений об оптимальном времени фармакологических и терапевтических воздействий на организм и пр. В хронобиологии число 24 представляет собой не произвольное членение суток на части, а феноменологическое сопряжение физиологических циклов организма с суточным циклом.
Механизмы фотосинтеза, на основе которых за счет потребления солнечной энергии производится само первичное живое вещество автотрофных организмов, связывают это биологическое производство с суточными циклами поступления животворной солнечной энергии к организмам. Выявление скрытой константы 24 в описанных особенностях эволюции генетических кодов позволило автору выдвинуть следующую рабочую хронобиологическую гипотезу [Petoukhov, 2001b; Петухов, 2004]: структуры генетического кода имеют через механизмы фотосинтеза (выступающих в роли первичных механизмов) связь с суточными 24-часовыми циклами поступления солнечной энергии на поверхность земли. С этой точки зрения известная привязка функционирования белковых систем организма к фазам суток имеет предшественников в аналогичных привязках на уровне генетического кода. И секреты структур генетических кодов надо искать с учетом структурных особенностей биологического феномена фотосинтеза, который до сих пор не воспроизводим в современных лабораториях и благодаря которому продуцируется само циклически существующее живое вещество, подлежащее затем наследственному кодированию в адекватных циклических формах. Одним из аргументов в пользу хронобиологической зависимости (природы?) структур генетического кода является полное совпадение матричных структур генетического кода с символьными таблицами «Книги перемен», на которых базируется восточная хрономедицина.
Автором опубликован также ряд других феноменологических правил по особенностям эволюции генетических кодов [Petoukhov, 2001b; Петухов, 2004].
Генетические тетра-множества, сегрегации в генетических кодах и параллелизмы с законами Менделя. Генетический код лежит в основе великого объединения живых организмов и в этом смысле он составляет основу жизни. Но какого типа законы лежат в основе самого генетического кода и генетических секвенций? Попытки ответить на этот вопрос привели автора к выдвижению рабочей гипотезы о реализации в генетической системе особых биологических правил («законов») расщеплений, имеющих аспекты формального родства с теми законами Менделя, на которых построена научная генетика и которые зачастую называются основными законами биологии.
Назовем тетра-множеством такое произвольное множество элементов, которое по критерию наличия или отсутствия значимого признака у его элементов расщеплено на два или три подмножества, количественные составы которых соотносятся в «канонических» пропорциях 1:3 или 2:2 или 4:0 или 1:2:1. Автором обращено внимание на широкое распространение «тетра-множеств» в системе генетического кодирования [Петухов, 2004а, б]. Приведем примеры.
Половые клетки (гаметы), через которые происходит передача наследственной информации, образуются в результате особого деления клеток, называемого мейозом. Еще Э.Шредингер в своей книге «Что такое жизнь? С точки зрения физика» обращал внимание на загадочную особенность природы, диктующей для самых разных видов организмов реализацию в результате мейоза типового набора из четырех половых клеток. В случае образования женской половой клетки (овогенез) возникают четыре клетки как тетра-множество с отношением расщепления 1:3, поскольку одна из клеток резко отличается по своей готовности к оплодотворению, увеличенному размеру и массе от трех других клеток. Эти три хилые клетки со временем дегенерируют и объединяются общим названием: редукционные тельца. При мейозе с образованием мужских половых клеток (сперматогенез) четыре половые клетки равноценны друг другу, т.е. в этом тетра-множестве реализуется отношение расщепления 4:0.
Совсем на другом конце биологических феноменов — при изучении архетипов человеческого сознания — создатель аналитической психологии Карл Юнг обнаружил существование аналогичного универсального архетипа: «Четверичность (также кватерность). Универсальный архетип, являющий собой логическую предпосылку всякого целостного суждения, часто имеет структуру 3+1, в которой один из элементов занимает особое положение, или обладает несхожей с остальными природой. Именно «четвертый», дополняя три других, делает их чем-то единым, символизирующим универсум» (цитируется по [Вер, 1998, с. 202]). И в связи с этим: «Мандала — изображение психического процесса, воссоздание нового центра личности. Символически выражается при помощи круга, симметричного расположения некоего четырехкратного количества. В ламаизме и тантра-йоге является инструментом созерцания (янтра), местом рождения и пребывания божества» [там же, с. 201].
В области собственно генетического кода пример тетра-множества дает четырехбуквенный алфавит кода, расщепленный по значимому признаку на два подмножества с соотношением их количественного состава 3:1. Три буквы А, С, G этого алфавита одинаковы для молекул ДНК и РНК и по этом признаку объединены в единое подмножество, а одна буква U (урацил) образует оппозиционное подмножество, поскольку не обладает данным свойством и при переходе от РНК к ДНК заменяется на букву Т (тимин). Эволюция генетических кодов дает другой пример тетра-расщепления с отношением 3:1. Речь идет о том, что из четырех семейств N-триплетов только одно семейство G-триплетов ни в одном из 17 известных генетических кодов не меняет кодовых значений своих триплетов, является эволюционно устойчивым.
Черно-белая мозаика на Рис. 10 наглядно демонстрирует, что каждое семейство N-триплетов, сгруппированное в одном из квадрантов октетной матрицы, также оказывается тетра-множеством из четырех подсемейств NN-триплетов с отношением 3:1 между подсемействами противоположного цвета. Каждое из подсемейств NN-триплетов в свою очередь является тетра-множеством, которое в разных генетических кодах может характеризоваться одним из канонических отношений сегрегации — 1:3 или 2:2 или 4:0 или 1:2:1. Но ни в одном из 17 генетических кодов ни разу не встречается тетра-расщепление подсемейства NN-триплетов в неканоническом отношении 1:1:1:1. Другими словами, в эволюции генетического кода исключена ситуация распада одного подсемейства NN-триплетов на четыре разных по кодовому значению триплета, каждый из которых кодировал бы разные аминокислоты или стоп-сигнал. Обязательным является именно объединение четырех триплетов подсемейства по их кодовым значениям в группы с одним из канонических отношений расщепления.
Известно, что по законам Менделя в первом и втором поколении гибридных организмов от скрещивания форм, различающихся по альтернативным признакам, реализуются тетра-множества с указанными выше каноническими отношениями (1:3 или 2:2 или 4:0 или 1:2:1) между количествами особей, наделенных одним из альтернативных признаков или признаком, представляющим их смешение. Отмечаемые количественные правила тетра-расщепления (сегрегации) генетического кода поставлены автором в параллель с известными количественными законами Менделя о расщеплении наследуемых признаков у гибридных организмов ([Петухов, 2004а, б]). Современное понимание происхождения законов Менделя связано с расщеплением пар гомологичных хромосом. На уровни генетических микроструктур, меньших уровня хромосом, законы Менделя не распространяются. Поэтому закономерности расщепления множеств элементов генетического кода по бинарно-оппозиционным признакам, вскрываемые в ходе данного исследования, имеют вполне самостоятельный характер и из законов Менделя никак не выводятся. Для ряда случаев тетра-множеств в системе генетического кодирования автором развивается теория проаллелей, носящих доминантный и рецессивный характер по аналогии с аллелями менделевской генетики. По одному из вариантов данной теории в качестве проаллелей выступают бинарные субалфавиты генетического алфавита (подробнее об этом см. [Петухов, 2004а, б]).
Генетические секвенции как тетра-множества. Не могут ли аналогичные принципы тетра-расщепления обусловливать также особенности состава генетических секвенций (текстов), кодирующих конкретные белки? Например, не могут ли генетические секвенции из некоторого обширного класса быть расщеплены по бинарно-оппозиционному признаку на подмножества триплетов с отношением 1:3 между их количествами?
Первые исследования этого проведены автором на отдельных примерах с положительным результатом. Так, рассмотрим простейший белок инсулин с секвенцией из 51 триплета (с учетом старт-кодона ATG число триплетов — 52 = 4х13):
- альфа-цепь (21 триплет, перед триплетом указан его порядковый номер): 1GGC® 2ATC® 3GTT® 4GAA® 5CAG® 6TGT® 7TGC® 8ACT® 9TCT® 10ATC® 11TGC® 12TCT® 13CTT® 14TAC® 15CAG® 16CTT® 17GAG® 18AAC® 19TAC® 20TGT® 21AAC ;
- бэта-цепь (30 триплетов, перед триплетом указан его порядковый номер): 1TTC® 2GTC® 3AAT® 4CAG® 5CAC® 6CTT® 7TGT® 8GGT® 9TCT® 10CAC® 11CTC® 12GTT® 13GAA® 14GCT® 15TTG® 16TAC® 17CTT® 18GTT® 19TGC® 20GGT® 21GAA® 22CGT® 23GGT® 24TTC® 25TTC® 26TAC® 27ACT® 28CCT® 29AAG® 30ACT.
Это множество из 51 триплетов расщеплено на подмножество из 13 G-триплетов и подмножество из 38 A-, C- и U-триплетов (с учетом старт-кодона ATG второе подмножество содержит 39 триплетов), находящихся в каноническом отношении 1:3.
Второй случайно взятый пример — секвенция для EG13077 у Escherichia:
ATG-GTT-CAG-AAG-CCC-CTC- ATT-AAG-CAG-GGA-TAT-TCA-CTG-GCA-GAG-GAA-ATA-GCC- AAC-AGC-GTC-AGT-CAC-GGC- ATT-GGG-TTG-GTG-TTT-GGT-ATC-GTT-GGG-CTG-GTG-TTG-CTA-CTG-GTT-CAG-GCG-GTG-GAT-CTT- AAT-GCC-AGC-GCC-ACA-GCG- ATA-ACC-AGC-TAC-AGC-CTC-TAT-GGC-GGC- AGT-ATG-ATC-CTG-CTG-TTC-CTC-GCT-TCG-ACG-CTC-TAT-CAC-GCC- ATT-CCT-CAT-CAA-CGG-GCA-AAA-ATG-TGG-CTG- AAG-AAA-TTT-GAC-CAT-TGC-GCT-ATT-TAC-CTG-TTG- ATT-GCC-GGA-ACC-TAC- ACG-CCG-TTT-TTG-CTG-GTG-GGG-CTG-GAT-TCT-CCG-TTA-GCG-CGC-GGG-TTG- ATG-ATT-GTT-ATC-TGG- AGC-CTG-GCA-TTG-CTG-GGT-ATT-CTG-TTT- AAA-CTG-ACC-ATC-GCG-CAC-CGA-TTC- AAA-ATT-TTA-TCT-CTG-GTG-ACC-TAT-CTG-GCG- ATG-GGC-TGG-CTG-TCG-CTG-GTG-GTA-ATT-TAT-GAA- ATG-GCA-GTT-AAG-CTC-GCG-GCG-GGC- AGC-GTT-ACC-TTA-CTG-GCG-GTA-GGC-GGC-GTG-GTT-TAT-CG-CTC-GGG-GTG- ATT-TTC-TAC-GTC-TGC-AAA-CGC- ATT-CCA-TAC-AAC-CAT-GCC- ATC-TGG-CAC-GGC-TTC-GTG-CTC-GGC-GGT-AGT-GTG-TGC-CAC-TTT-CTG-GCG- ATC-TAT-TTG-TAT-ATT-GGG-CAG-GCG-TAA
Эта секвенция из 220 триплетов расщеплена на подмножество 55 А-триплетов (подчеркнуты) и подмножество остальных 165 остальных триплетов (50 С-триплетов, 69 Т-триплетов, 46 G-триплетов) с отношением 55:165=1:3. Другими словами, можно говорить о том, что в данной генетической секвенции представлено тетра-множество тех же четырех семейств N-триплетов с расщеплением 1:3.
Выдвигается программа систематического «гибридологического» анализа генетических секвенций как тетра-множеств с возможным приложением к ним понятий доминантных и рецессивных проаллелей. Этот анализ должен уточнить, в какой степени процесс образования генетических текстов с формальной точки зрения аналогичен процессу гибридизации организмов. В случае широкого распространения подобных тетра-расщеплений в организации генетических текстов, число допустимых вариантов состава этих текстов оказывается сильно ограниченным и может являться одной из причин того, что далеко не все мыслимые генетические секвенции кодируют белки.
Почему число генетически кодируемых аминокислот равно 20? Известно много попыток различных исследователей ответить на этот фундаментальный вопрос. Автор предлагает новый ответ: множество 20 аминокислот представлено в генетическом коде потому, что оно состоит из двух альтернативных подмножеств из 8 и 12 аминокислот [Petoukhov, 2001b; Петухов 2004a].Тем самым, исходный вопрос сведен к существенно иному, более глубокому вопросу: почему существуют альтернативные группы из 8 и 12 аминокислот в едином генетическом наборе из 20 аминокислот?
Возможный ответ на этот новый фундаментальный вопрос связан с тем, что эти два подмножества аминокислот составляют предмет двух самостоятельных ветвей эволюции внутри генетического кода, как описано выше. Именно биологический механизм тетра-расщепления может быть ответственным за параллельное существование двух таких альтернативных групп в связи с очевидным тетра-представлением данных чисел: 8 = 4х2 и 12 = 4х3. В данном тетра-представлении число 8 содержит число 2 в качестве модульного блока, а число 12 – число 3 в аналогичной роли. При этом в случае подмножества 8 аминокислот каждый модульный блок содержит две аминокислоты, а в случае подмножества 12 аминокислот каждый модульный блок состоит из трех аминокислот. Отметим формальную аналогию этим двух- и трехсоставным модулям из совсем другой области – физики элементарных частиц. Согласно кварковой гипотезе, барионы состоят из трех кварков, мезоны – из кварка и антикварка. Не могут ли формальные элементы теории кварков быть перенесены в сферу структур генетического кодирования? Будущее покажет.
Исследования выявили, что типовые расщепления множества 20 аминокислот на подмножества из 8 и 12 аминокислот происходят не по единственному, а по нескольким вариантам в зависимости от вида бинарно-оппозиционного признака, по которому расщепление имеет место. Речь идет о том, что не только пара оппозиционных признаков «высоковырожденная-низковырожденная» аминокислота приводит к распадению сообщества 20 аминокислот на 8 и 12 аминокислот. Сходные расщепления, но с другим составом аминокислот в образующихся подмножествах из 8 и 12 аминокислот дают такие бинарно-оппозиционные признаки, как «комплементарная-некомплементарная» аминокислота, «восьмеричная-невосьмеричная» аминокислота (по количеству протонов в молекуле аминокислоты), «высокоуглеродная-низкоуглеродная» аминокислота (по количеству атомов углерода в молекуле аминокислоты) (см. /Петухов, 2004; Petoukhov, 2004c/). По мнению автора, этот многовариантный феномен типового расщепления множества 20 аминокислот связан с обеспечением параллельных каналов биологической информации, работающих с разными бинарно-оппозиционными признаками.
Подтверждающий пример выдвигаемого положения о том, что реализация подмножеств 8 и 12 аминокислот в генетическом коде обусловлена самим принципом их тетра-строения из модулей 2 и 3 (8=4х2 и 12=4х3) дает Рис. 12. Он показывает реальное разделение множества 20 аминокислот на подмножество из 8 «комплементарных» и 12 «некомплементарных» аминокислот. Напомним, что некоторые пары аминокислот имеют такое соответствие между своими триплетами, что триплеты, кодирующие одну аминокислоту из этой пары, являются антикодонами тех триплетов, которые кодируют вторую аминокислоту из этой пары. Такие аминокислоты называются «комплементарными» (по своим триплетам) в отличие от остальных «некомплементарных» аминокислот. На Рис. 10 первое подмножество состоит из четырех таких пар аминокислот, каждая из которых кодируется триплетами одного из четырех семейств N-триплетов. А второе подмножество сходным образом состоит из четырех таких троек аминокислот, каждая из которых также кодируется триплетами одного из этих четырех семейств N-триплетов. (Подробнее об этом см. [Петухов, 2004а, б]).
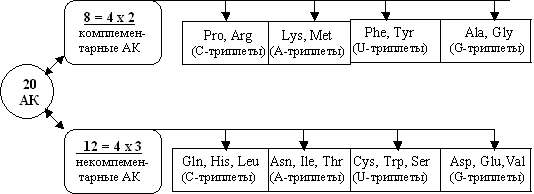
Рис. 12. Множество 20 аминокислот (АК) как объединение двух подмножеств из 8 комплементарных и 12 некомплементарных аминокислот. Каждое из этих подмножеств представляет собой тетра-объединение модульных блоков из двух и трех аминокислот соответственно, относящихся сходным образом к четырем семействам N-триплетов.
Матрицы плотности. Одно из перспективных направлений для попыток осмысления феноменов генетического кода с позиций квантовой физики определено предлагаемой автором интерпретацией числовых геноматриц как матриц плотности статистической квантовой механики. Как известно, понятие волновых функций из обычной квантовой механики применимо для описания систем, состоящих всего из нескольких частиц. Если же частиц много, то единственный путь исследования их системы с позиций квантовой физики лежит через исследование ее матриц плотности. В квантовой биологии сложных систем нет альтернативы попыткам поиска матриц плотности биосистем. Матрица плотности должна удовлетворять нескольким простым условиям (см. например, [Ландау, Лифшиц, 1989, с. 61]). В частности, ее след должен быть равен единице. Легко проверить, что описанные выше числовые геноматрицы, например, (Pi мульт)(n) или (Фi мульт)(n) (Рис. 9) при их нормировании к единичному следу, т.е. делению на сумму их диагональных членов, удовлетворяют всем формальным требованиям к матрицам плотности. Исследование квантового уравнения Лиувилля, которому удовлетворяют матрицы плотности, открывает дополнительные возможности для построения моделей и теорий биологических феноменов разного уровня.
Сопряжение с теорией блоковых кодов. Проблема системы генетического кода специфична в том, что она должна осмысливаться как с позиций физико-химических знаний о механизмах, делающих возможным само существование данной системы, так и с позиций математической теории кодирования для понимания особенностей исполнения ею информационно-кодовых задач. Описанное матричное представление системы генетического кодирования обращает внимание на возможность его сопряжения с развитой теорией блоковых кодов, известной в компьютерной информатике. Это предлагаемое автором сопряжение представляется особо перспективным для познания генетической информатики.
В компьютерах код определяется как представление множества символов последовательностями, состоящими из единиц и нулей. При декодировании сообщения не должно возникать проблем с тем, какую букву представляет элемент кода. Одним из способов достижения такого однозначного декодирования является кодирование всех символов бинарными последовательностями одинаковой длины. Такой код называется блоковым, а его развитая теория использует множество красивых понятий и результативных методов [Андерсен, 2003, с. 753]. Все элементы каждой из рассмотренных выше геноматриц Р и Р(3) (Рис. 2), состоящих из 4 моноплетов и 64 триплетов соответственно, представляют собой кодо-генетические последовательности одинаковой длины. Но они являются не бинарными, а образованными на базе четырехбуквенного (С, G, A, U) алфавита генетического кода, что осложняет применение теории блоковых кодов к их изучению.
Однако, система четырех азотистых оснований (букв генетического алфавита) является носителем трех видов бинарно-оппозиционных признаков; это позволяет ввести понятие бинарных субалфавитов по признакам и увидеть то, что каждая генетическая секвенция представляет собой связку трех параллельных последовательностей на трех разных бинарных языках [Петухов, 2001]. В этих субалфавитах каждая буква кода характеризуется следующим бинарным символом: в первом субалфавите C=U=1, A=G=0 (по альтернативному признаку «пиримидин или пурин»); во втором субалфавите С=А=1, U=G=0 (по признаку наличия или отсутствия свойства аминомутируемости); в третьем субалфавите C=G=1, A=U=0 (по признаку трех или двух комплементарных водородных связей). Учет этих бинарных субалфавитов позволяет каждый буквенный n-плет матрицы Р(n) заменить ее бинарным эквивалентом с позиций одного из трех бинарных субафлавитов. Например, при такой замене буквенный триплет CGA превращается при его прочтении с позиций первого бинарного субалфавита в бинарный триплет 100; с позиций второго субалфавита – 101; с позиций третьего субалфавита – 110. Соответственно каждая матрица Р(n) при такой замене с позиций одного из трех субалфавитов становится матрицей, содержащей все бинарные полиплеты длины n, а потому представляет собой систематизированный блоковый код с полным набором бинарных последовательностей длины n. С учетом трех бинарных субалфавитов каждая матрица Р(n) является скрытым объединением трех разных бинарно-алфавитных матриц Р(n)1, Р(n)2, Р(n)3, соответствующие этим субалфавитам. На Рис. 13 показан пример тетра-алфавитной матрицы Р(2) и ее трех бинарно-алфавитных ипостасей Р(2)1, Р(2)2, Р(2)3.

Рис. 13. Матрица Р(2) и ее три бинарно-алфавитные ипостаси Р(2)1, Р(2)2, Р(2)3.
К этой совокупности трех бинарно-алфавитным ипостасей геноматриц Р(n) уже вполне приложима теория блоковых кодов с ее понятиями порождающих матриц, расстояния Хэмминга, кода Грея, двойственного кода и пр. Вся система полиплетов генетического кодирования аминокислот и белков всех живых организмов предстает при этом как система трех бинарно-алфавитных иерархических семейств Р(n)1, Р(n)2, Р(n)3. Одной из специфик данных кодовых семейств является то, что коды с последовательностями разной длины системно взаимосвязаны через их матричные представления. Совокупное изучение этих трех семейств или трех бинарно-алфавитных ипостасей архматрицы Р(N) (где N достаточно большое для кодирования самого длинного белка N-плетом) способно многое сказать о природе и скрытых свойствах общебиологической системы генетического кодирования. В геноматрицах Р(3n) далеко не все 3n-плеты кодируют реальные белки, а потому оказывается полезным рассмотрение разреженных геноматриц, т.е. матриц с нулями вместо «незначащих» полиплетов в них. У любых двух видов организмов генетические последовательности, кодирующие первичное строение всей белковой системы в них, заключены соответственно в двух разных семействах геноматриц Р(n), которые могут отличаться как по своему размеру (с учетом различия в длинных белках у этих видов), так и по характеру разреженности геноматриц, отражающему состав кодируемых белков. Анализ характера разреженности геноматриц у разных видов организмов, а также взаимосвязи между разреженными геноматрицами, относящимися к белкам разной длины в одном организме, представляется важным новым направлением системного исследования белковой кооперации и эволюции в живой природе. Полезным математическим приемом в этом начатом исследовании является разложение разреженных матриц Р(3n) на тензорные произведения соответствующих разреженных матриц Р(3)к, триплеты которых кодируют аминокислоты в рассматриваемых системах белков. На данном пути можно ожидать, в частности, ответа на вопрос, почему лишь некоторые категории полиплетов кодируют белки.
Гипотеза Г.Стента о структурной связи генетического кода и символьной системы «Книги перемен». Крупный американский молекулярный генетик Г.Стент опубликовал в 1969 году книгу, в которой отметил интересный исторический параллелизм: «Общие свойства генетического кода несут любопытное сходство с другой символической системой, созданной более 3000 лет назад для постижения природы жизни, а именно древнекитайской «И цзин» или «Книги перемен». … «Естественный» порядок «И цзин» может теперь рассматриваться как генератор ряда нуклеотидных триплетов, в котором представлены многие отношения генетических кодонов …. Возможно, исследователи все еще загадочного происхождения генетического кода должны учитывать обширные комментарии к «И цзин» для получения ключей к решению их проблемы» [G. Stent, 1969, с.64].
Речь идет об ученом, чьи книги по молекулярной генетике переведены на многие языки мира, в том числе на русский, и используются в качестве учебников молекулярной генетики в ВУЗах. Впоследствии ряд других исследователей поддержал публикацию Стента о возможной связи структур генетического кода с символьной системой сакраментальной древней книги, оказавшей огромное влияние на всю восточную культуру, медицину, науку и другие сферы жизни. Литературные источники отмечают, что «»И цзин» — книга, которую мудрецы и ученые всех поколений полагали ключом к разгадке таинств Природы и неисчерпаемой сокровищницей метафизической премудрости, объясняющей все явления Вселенной» [Ермаков, 1998, с.92].
В частности, Стента поддержал нобелевский лауреат по молекулярной генетике Ф. Жакоб, утверждавший: «Возможно, именно через древнекитайскую «Книгу перемен» удастся установить связь между генетическим кодом и языком» [F.Jacob, 1974]. В целом, в молекулярной генетике уже десятки лет существует положение о необходимости углубленного анализа названных параллелизмов и их возможного расширения. Описанное в настоящей работе матричное представление системы генетического кода позволило получить существенные дополнительные материалы к этой области исследований.
Напомним, что в основе названной китайской символьной системы лежит представление о четырех базовых сущностях – молодых и старых инь и ян, каждая из которых обозначается парой соответствующих бинарных символов в виде непрерывной черты (или символа 1) и прерывной черты (или символа 0). Эти четыре символа представляются в форме матрицы второго порядка (Рис. 14, вверху).
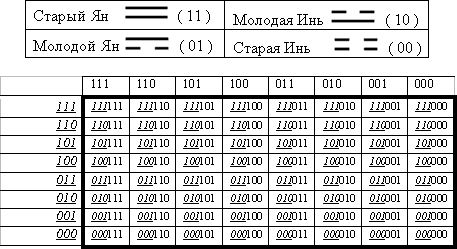
Рис. 14. Базовые таблицы «Книги перемен» для четырех диграмм молодых и старых инь и янь (вверху) и для 64 гексаграмм в порядке Фу-си (внизу).
Также в «Книге перемен» важное место отведено октетной таблице 64 гексаграмм, расположенных в порядке Фу-си [Щуцкий, 1997; Еремеев, 1993; Кобзев, 1994; Петухов, 2001]. Эта исторически знаменитая таблица воспроизведена в бинарных символах 0 и 1 на Рис. 14 внизу. Каждая гексаграмма в этой таблице составлена из двух независимых друг от друга триграмм, символизирующих те строку и столбец, на пересечении которых находится данная гексаграмма (подчеркивая различие в их природе, их называют триграммами «земли» и «неба», внутренней и внешней триграммой, пространственной и временной триграммой и т.д.) [Щуцкий, 1997, с. 101]. Согласно «Книге перемен» эти две таблицы являются всеобщими природными архетипами, наиболее сообразными природными системами.
Удивительным является то, что эти две исторически знаменитые матрицы связаны с геноматрицами Р и Р(3) генетического кода [Петухов, 2001]. Действительно, если в геноматрицах Р и Р(3) на Рис. 2 заменить каждый их полиплет (т.е. моноплет и триплет соответственно) на его координатный номер, представляющий собой объединение бинарных номеров строки и столбца, на пересечении которых стоит данный полиплет, то мы получим две такие бинарно-числовые матрицы, которые в точности совпадают с матрицами на Рис. 14, существующими в мировой культуре уже несколько тысяч лет на заявленном положении всеобщих природных архетипов. Древние китайцы ничего не знали о генетическом коде, открытом недавно западной наукой, а автор статьи, конструируя бипериодические геноматрицы на основе чисто академических данных, никак не использовал таблицы «Книги перемен». Но в итоге обнаружилось формальное совпадение двух названных пар матриц и оказалось, что бинарные представления построенных автором геноматриц известны уже тысячи лет.
Нетривиальные совпадения этим не ограничиваются. Числа 2 и 3, которые в генетическом коде реализованы в информационно значимом числе водородных связей у комплементарных оснований генетического алфавита, издревле являются основой китайских числовых систем [Кобзев, 1994, с. 15]. Другой пример связан с опубликованным [Петухов, 2001, с. 61] числовым представлением октетной геноматрицы Р(3) через количества атомов в кольцах азотистых оснований (A=G=9, C=U=T=6). В соответствующей числовой геноматрице суммы чисел в каждом из восьми столбцов, соответствующих восьми бинарным триграммам, образуют числовой ряд 144, 168, 168, 192, 168, 192, 192, 216. Но, как выяснилось много позже названной публикации, этот числовой ряд для восьми китайских триграмм известен издревле и называется в системе знаний «Книги перемен» рядом «счетных палочек» [Виногродский, 2003, с. 269-292].
Пара чисел 8 и 12, характеризующая описанные выше канонические наборы аминокислот, является «стандартной мерой альтернативных членений пространства-времени на китайских хронотопограммах… Стереометрически числа 8 и 12 взаимосвязаны также в качестве основных параметров куба и октаэдра. У куба 8 вершин и 12 ребер, у октаэдра 8 граней и 12 ребер. Оба правильных многогранника издревле были для китайских мыслителей базовыми мироописательными моделями. … Идея сочетания 8 и 12 как символа пространственно-временного универсума отражена в архитектонике «Книги перемен»» [Кобзев, 1994, с. 39-40].
Молодые и старые инь и янь символизируются по «Книге перемен» числами 6, 7, 8 и 9 [Щуцкий, 1997, с. 22, 522]. Именно эти числа характеризуют количество протонов в элементах, из которых состоят буквы генетического алфавита: углерод С имеет 6 протонов (порядковый № 6 в таблице Менделева), азот N – 7 протонов, кислород О – 8 протонов, аминогруппа NH2 – 9 протонов [Петухов, 2001]. Ограниченный объем статьи не позволяет продолжить этот перечень параллелизмов, в связи с которыми при проведении вполне академических исследований структур генетического кода возникает впечатление, что мы идем по коридору обнародованных в Древнем Китае формализмов и числовых систем [Петухов, 2001].
Перспективным представляется сопряжение бинарно-числовых представлений системы геноматриц с бинарной геометрофизикой, оперирующей близкими понятиями и также затрагивающей древние бинарные системы «Книги перемен» [Владимиров, 2002].
Дополнение 1: золотые геноматрицы второй категории. Оказывается, что символьные геноматрицы Р(n) (см. Рис. 2) при их представлении через числа водородных связей азотистых оснований (C=G=3, A=U=2) порождают еще одну категорию числовых матриц, которые связаны квадратичной зависимостью с золотыми матрицами ФК иного типа, чем Фмульт(n) на Рис. 4, 5. Кратко проиллюстрируем это на примере октетной матрицы Р(3) с ее триплетами. Обозначим названную новую категорию матриц через ВК, где К=1, 2, 3. Эти матрицы ВК (Рис. 15) получаются из геноматрицы Р(3) путем совершения двух действий: 1) замены каждого триплета моноплетом из той его буквы, которая расположена на позиции триплета, соответствующей значению индекса К: например, триплет CGA при образовании матрицы В1 представляется буквой его первой позиции C, матрицы В2 – буквой второй позиции G, матрицы В3 – буквой третьей позиции A; 2) замены каждой буквы на число водородных связей соответствующего азотистого основания: С=G=3, A=U=2.

Рис. 15. Вверху: октетные матрицы B1, B2, B3, полученные из символьной матрицы триплетов Р(3) путем выписывания соответственно только кодовой буквы на первой, второй и третьей позиции триплетов и последующей заменой этой буквы числом ее комплементарных водородных связей C=G=3, A=U=2. Внизу: три золотых матрицы ΦК, все элементы которых равны золотому сечению φ = (1 + 51/2)/2 = 1, 618… или его обратной величине τ = φ-1. Матрица ΦК2 равна учетверенной матрице (BК).
Так полученные числовые матрицы ВК содержат всего два вида чисел – 2 и 3 — с разным расположением. Эти матрицы связаны квадратичным образом с числовыми золотыми матрицами ФК, где К = 1, 2, 3, в которых аналогично расположены два иррациональных числа: золотое сечение φ и обратная ему величина φ-1 (см. Рис. 15, где τ = φ-1). При этом 4 х ВК = ФК2. Эти матрицы ВК, имеющую скрытую «подложку» из золотых матриц ФК, возникли в ходе развития содержательной концепции позиционирования бинарных языков при считывании триплетов [Петухов, 2003].
Эти золотые матрицы ФК обладают интересными свойствами. Например, попарное перемножение разных матриц ФК между собой в произвольном порядке, например, Ф1 х Ф2 = Ф2 х Ф3 = Ф1 х Ф3 дает одну и ту же матрицу с одинаковым значением всех элементов, равным 10. Возведение в квадрат любой из этих золотых матриц ФК дает матрицу, в которой просто все φ и φ-1 заменены соответственно на числа 12 и 8.
Добавление 2: геноматрицы как наследуемые метрические тензоры. Взаимосвязанные семейства геноматриц Рмульт(n) и Фмульт(n) имеют ценную геометрическую трактовку. Любая геноматрица Рмульт(n) может интерпретироваться как метрический тензор в 2n-мерном евклидовом пространстве с таким аффинным репером, координаты векторов которого перечислены в строках (или столбцах) золотой матрицы Фмульт(n). Например, на евклидовой плоскости в репере с «золотыми» векторами е1(φ, φ-1) и е2(φ-1, φ), соответствующими строкам матрицы Фмульт, метрический тензор имеет вид геноматрицы Р = [3 2; 2 3]. Известна фундаментальная роль метрического тензора для евклидовой геометрии. В этой связи матричный подход к генетическому кодированию, которое обычно связывается только с наследованием первичного строения белков, выводит на феномен врожденных знаний организмов об окружающем пространстве и времени. Представление о физиологических основаниях геометрии имеет давнюю историю. Например, активный сторонник такого представления А.Пуанкаре, не зная о генетическом коде, утверждал, что возникновение у индивидуума самого понятия пространства и геометрии обусловлено деятельностью кинематической организации тела. Предлагаемое понимание геноматриц как метрических тензоров, помимо порождения новой концепции генетических оснований геометрии, позволяет моделировать биологическое формообразование как реализацию генетических потенций, связанных с такими наследуемыми метрическими генотензорами. Последние, видимо, отражают специфику реальных физических механизмов, участвующих в обеспечении генетических явлений.
Наследование информации вообще может базироваться на передаче потомкам алгоритмически связанной системы подобных тензоров, в компонентах которых реализованы те или иные информационно значимые параметры генетических элементов. Ситуация с числами 2 и 3 водородных связей в роли компонент тензора Р ассоциируется со схемой Гелл-Манна и Неемана классификации адронов, каждый из которых соответствует в ней независимой компоненте некоторого тензора. Автор распространяет описанное представление реальных генетических параметров в форме компонент тензоров также на другие числовые характеристики генетических элементов, например, на числа 6 и 9 атомов в кольцах пиримидиновых и пуриновых оснований.
В настоящее время данное направление работ по биоинформатике и геометризации биологии дополнительно развивается по инициативе автора в рамках программы многолетнего сотрудничества Российской и Венгерской Академий наук, а также программ Международной ассоциации симметрии (со штаб-квартирой в Будапеште, http://us.geocities.com/symmetrion/) и Международного общества симметрии в биоинформатике (со штаб-квартирой во Флориде, США, http://polaris.nova.edu/MST/ISSB).
В заключение автор выражает благодарность академику К.В.Фролову, профессорам Ю.С.Владимирову, Д.Дарвашу, В.А.Копцику, Я.Бэму, Б.Санто, М.Хи и всем участникам семинаров по проблемам симметрии и метафизики Института машиноведения РАН и кафедры теоретической физики физического факультета МГУ за помощь в данной работе.
Литература:
- Андерсон Дж.А. Дискретная математика и комбинаторика. – М., 2003.
- Аракелян Г.Б. Фундаментальные безразмерные величины. – Ереван, АН Армян. ССР, 1981.
- Вер Г. «Карл Густав Юнг», Свердловск, Урал Лтд, 1998, 210 с.
- Виногродский Б.Б. Даосская алхимия бессмертия. – М., «София», 2003.
- Владимиров Ю.С. Метафизика.- М., Бином, 2002, 534 с.
- Еремеев В.Е. Чертеж антропокосмоса. – М., АСМ, 1993, 383 с.
- Ермаков М.Е. Китайская геомантия. – СПб, Петербургское Востоковедение, 1998.
- Кобзев А.И. Учение о символах и числах в китайской классической философии. – М., Восточная литература, 1994, 432 с.
- Конопельченко Б.Г., Ю.Б.Румер. Классификация кодонов в генетическом коде. — ДАН СССР, т. 223, №2, 471-474, 1975.
- Ландау Л.Д., Лифшиц Е.М. Квантовая механика. Нерелятивистская теория. 4-е изд.– М., Наука, 1989
- Математические методы для анализа последовательностей ДНК (под ред. М.С. Уотермена), М., Мир, 1999.
- Петухов С.В. Биосолитоны. Основы солитонной биологии. – М., 1999, 288 с.
- Петухов С.В. Бипериодическая таблица генетического кода и число протонов. /Предисловие К.В.Фролова. – М., 2001, 258 с.
- Петухов С.В. Генетический код и обобщенные матрицы Фибоначчи. — Труды Международной конференции «Проблемы гармонии, симметрии и золотого сечения в природе, науке и искусстве», Винница, 2003 г, стр. 161-169. Сборник научных трудов Винницкого гос. аграрного университета, вып. 15, Винница, 2003 г.
- Петухов С.В. Симметрии в биологии. – Приложение к книге: Шубников А.В., Копцик В.А. «Симметрия в науке и искусстве», 3-е издание, М, 2004a, с. 482-513.
- Петухов С.В. О теории бинарных языков генетического кода и генетической алгебре. — Депонировано в ВИНИТИ РАН 02.02.2004b, 30 с., № 182-В2004 (Указатель ВИНИТИ «Депонированные научные работы», № 4, 2004 г.).
- Петухов С.В. Правила расщепления генетического кода и их параллелизм с законами Менделя. — Депонировано в ВИНИТИ РАН 07.06.2004c, 30 с., № 964-В2004 (Указатель ВИНИТИ «Депонированные научные работы», № 8, 2004 г).
- Стахов А.П. Новая математика для живой природы. – М., ITI, 2003, 261 c.
- Хи М. Симметрия в структуре генетического кода. – Труды Третьей Всероссийской конференции «Этика и наука будущего», Москва, Дельфис, февраль 2003, с. 68-75.
- Щуцкий Ю.К. Китайская классическая «Книга перемен» – М., 1997, 605 с.
- Cook T.A. The curves of life. — L.: Constable and Co, 1914, 490 p.
- He M., Petoukhov S., Ricci P. Genetic Code, Hamming Distance and Stochastic Matrices. – Bulletin for Mathematical biology, 2004 (в печати)
- Jacob F. Le modele linguistique en biologie. — Critique, Mars 1974, tome XXX, №322, p.197-205
- Petoukhov S.V. Genetic Code and the Ancient Chinese «Book of Changes». — Symmetry: Culture & Science, vol. 10, №3-4, 1999, р.211-226.
- Petoukhov S.V. Genetic Codes I: Binary sub-alphabets, bi-symmetric matrices and golden section.- Symmetry in Genetic Information, ed. Petoukhov S.V., special issue of the journal «Symmetry: Culture and Science», Budapest, 2001a: Internat. Symmetry Foundation, р. 255-274
- Petoukhov S.V. Genetic Codes II: Numeric Rules of Degeneracy and a Chronocyclic Theory. — Symmetry in Genetic Information, ed. Petoukhov S.V., ISBN 963216 242 0, special double issue of the journal «Symmetry: Culture and Science», Budapest, 2001b: International Symmetry Foundation, р. 275-306.
- Petoukhov S.V. The Biperiodic Table and Attributive Conception of Genetic Code. A Problem of Unification Bases of Biological Languages. – In: Proceedings of «The 2003 International Conference on Mathematics and Engineering Techniques in Medicine and Biological Sciences», session «Bioinformatics 2003», Las Vegas, June 23-26, 2003.
- Petoukhov S.V. Attributive conception of genetic code, its bi-periodic tables and a problem of unification bases of biological languages.-«Symmetry: Culture and Science», 2003, # 1-4, p.40-59
- Stent G.S. The Coming of the Golden Age. — N-Y, The Natural History Press, 1969.
- Wittmann H.G. Ansatze zur Entschlusselung des genetishen Codes. – Die Naturwissenschaften, 1961, B.48, 24, S. 55
С.В. Петухов, Метафизические аспекты матричного анализа генетического кодирования и Золотое сечение // «Академия Тринитаризма», М.,
|
|