|
|
|
В.Ю. Татур
12 июня 2013 года исполняется 15 лет, как официально стартовал российско-белорусский проект «СКИФ», его формулирование, подбор участников и последующее утверждение в 1999 г. как проекта Союзного государства России и Беларуси.
В этом году так же исполняется 20 лет официальной презентации рекурсивной суперкомпьютерной системы RS30, разработанной ЗАО «РеСКо» на основе машин с динамической архитектурой, и 10 лет формированию уникального проекта «МИССИЯ» (Мобильная Информационная Среда С Интеллектуальным Ядром) на основе созданных к 2003 г. в России технологий и программных продуктов.
Проект СКИФ
(СуперКомпьютерная Инициатива «Феникс»)
Сначала этот проект носил название СКИБР (СуперКомпьютерная Инициатива Беларуси и России). Путь к этому проекту был долгий, через интеграцию многих направлений, который развивались и как частные проекты ( ЗАО «Мультикон», ЗАО «РеСКо»), и как проекты РАН (Т-системы, ИПС РАН и МДА, СПИИ РАН - Санкт-Петербургский институт информатики и автоматизации РАН)
Суть проекта «СКИФ» была в создании модульной высокопроизводительной двухуровневой гибридной вычислительной системы с динамической архитектурой и параллельной обработкой данных.
Этот проект родился из объединения в конце 1997 г. двух фирм ЗАО «Мультикон» и ЗАО «РеСКо» в одну ООО «Суперкомпьютерные системы», в которой я стал работать на должности Генерального директора. Объединение произошло после участия этих фирм в разработке компьютерных систем для американской компании «Nick& C Corporation». ЗАО «Мультикон» разрабатывала однородно-вычислительные среды, а ЗАО «РеСКо» - машины с динамической архитектурой (МДА, на основе разработок В.А. Торгащова и И.В. Царева из Санкт-Петербургский институт информатики и автоматизации РАН, СПИИ РАН) и поддерживало исследования С.М. Абрамова и А.И. Адамовича по Т-системам, которые они проводили в ИПС РАН (Институт программных систем, Переславль-Залесский, Ярославская область, сейчас институт носит имя своего основателя, д.т.н., профессора, академика РАЕН А.К. Айламазяна).
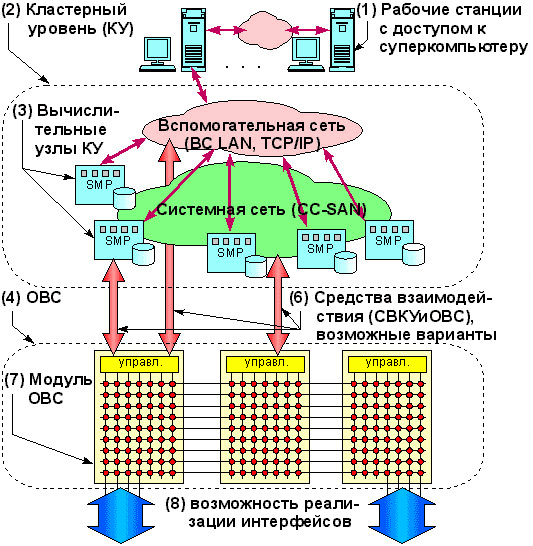
Новая архитектура получила название "МиниТера". Ее отличие от других состояло в том, что она представляла собой двухуровневую масштабируемую архитектуру, обеспечивающую возможность совместного (в рамках одной вычислительной системы) использования двух различных архитектурных аппаратных решений (уровней):
1-й уровень - классический кластер (тесносвязанная сеть) из вычислительных узлов реализованных с использованием компонент широкого применения (стандартных микропроцессоров, модулей памяти, жестких дисков и материнских плат, в том числе материнских плат с поддержкой SMP);
2-й уровень - модули однородной вычислительной среды (ОВС)—вычислительная среда с топологией плоской решетки из большого числа микропроцессоров, объединенных потоковыми линиями передачи данных.
Двухуровневая масштабируемая архитектура
Для этих двух архитектурных аппаратных решения были свойственны различные подходы к организации параллельных вычислений:
- для кластеров это были программные средства—Т-система, MPI, PVM, Norma, и др.
- в архитектуре ОВС для организации параллельного исполнения задачи наиболее адекватна была модель потоковых вычислений (data-flow).
Предпосылкой объединения двух—кластерного и потокового,—аппаратных решений и соответствующих им программных средств для организации параллельной обработки в рамках одной вычислительной системы, являлось то, что эти два подхода своими сильными сторонами компенсировали недостатки друг друга. Тем самым, в общем случае, каждая прикладная проблема могла быть разбита на:
- фрагменты со сложной логикой вычисления, с крупноблочным (явным статическим или скрытым динамическим) параллелизмом—такие фрагменты эффективно реализовывать на кластерном уровне;
- фрагменты с простой логикой вычисления, с конвейерным или мелкозернистым явным параллелизмом, с большими потоками информации, требующими обработки в реальном режиме времени—такие фрагменты эффективно реализовывать в РВМ (реконфигурируемых вычислительных модулях).
Потоковый уровень позволял эффективно реализовывать те задачи (фрагменты прикладных проблем), которые неэффективно решаются на кластерном уровне вычислительной системы.
При таком построении вычислительной системы пропорции деления прикладной проблемы определяли:
- пропорции объемов программного обеспечения для нее в части кластерного и потокового уровней;
- эффективный состав вычислительной системы для данной прикладной задачи—количество вычислительных узлов кластерного и потокового уровня, набор и характеристики необходимого коммутационного оборудования и т.д.,
Таким образом новая архитектура позволяла для каждого типа задач оптимизировать вычислительную систему по количеству вычислительных модулей кластерного уровня и количеству вычислительных блоков ОВС (РВС). При этом архитектура являлась открытой и масштабируемой, то есть не накладывала жестких ограничений на программно-аппаратную платформу узлов кластера, топологию вычислительной сети, конфигурацию и диапазон производительности суперкомпьютера.
Обращаю внимание, это – 1997 г. К этому времени был создан первый в мире работающий персональный суперкомпьютер «Мультикон» (о нем расскажу далее), выпущенный на отечественной элементной базе, и вычислительная система с динамической архитектурой RS30 и ее развитие до RS40 в 1995 г.
Россия в 1997-1998 гг., можно сказать, лежала в руинах. Только инфляция подскочила с 11% в 1997 г. до 84% в 1998 г. В этих условиях было принято решение подключить к этому проекту Национальную Академию Наук (НАН) Беларуси и ее предприятия, поскольку научно-техническая инфраструктура Беларуси в то время имела хоть какое-то общее управление, без которого решить такую сложную задачу в кратчайшие сроки было просто невозможно. Я и Вадим Михайлович Крохин провели с белорусскими коллегами предварительные переговоры, и 22.04.1998 г. на мое имя пришло приглашение от Президента НАН Беларуси провести в Минске научно-техническое совещание по предполагаемому проекту.

|
| |
Приглашение в Минск
И вот, в мае 1998 г., я и В.М. Крохин привезли в Минск делегацию специалистов, в том числе из ИПС РАН, и работающий образец «Мультикона» с предложением для НАН Беларуси и завода «Интеграл» об их участии в совместной программе. Сначала я ее назвал «СКИБР» (СуперКомпьютерная Инициатива Беларуси и России), а потом с согласия партнеров переименовал в 1999 г. в «СКИФ» (СуперКомпьютерная Инициатива «Феникс»), которое в последствии стало шифром этой программы и обобщенным названием вычислительных систем. Тогда, в мае 1998 г., речь еще не шла о программе Союзного государства. Мы надеялись, что НАН Беларуси и минский «Интеграл» сами смогут реализовать эту программу. На совещании Минске была продемонстрирована не только работа «Мультикона», но и рассказано о возможностях Т-системы, ее будущем, об основных аспектах будущей гибридной вычислительной системы. В итоге приняли решение провести в июне 1998 г. в Переславль-Залесском на территории ИПС РАН развернутое организационно-техническое совещание.
В этом совещании со стороны Беларуси должны были принять участие: Президент НАН Беларуси (НАНБ) А.П. Войтович, зам. Главного Ученого секретаря Президиума НАНБ О.И. Семенков, ведущий конструктор НПО «Интеграл» В.В. Равко, зам. начальника НИИ ЭВМ В.П. Качков, зам. директора ИТК НАНБ В.В. Анищенко, зав. отделом НИП «Информационные технологии» НАНБ А.В. Шаренков.
Со стороны России: директор ИПС РАН А.К. Айламазян, директор ИЦИИ ИПС РАН Г.С. Осипов, директор ИЦМС ИПС РАН, зав. лаб. «Ботик» С.М. Абрамов, директор ИЦСАиИО ИПС РАН А.М. Цирлин, директор ИЦПУ ИПС РАН В.И. Гурман, зам директора ИЦМИ ИПС РАН Я.И. Гулиев, Генеральный директор ООО «Суперкомпьютерные системы» В.Ю. Татур, зам. Директора по технологиям ООО «Суперкомпьютерные системы» В.И. Геворкян, главный специалист ООО «Суперкомпьютерные системы» Г.И. Бачериков.
Огромную помощь в организации совещания в Минске и последующей работе оказали Первый заместитель Председателя Президиума НАНБ, академик П.А. Витязь и зам. Главного Ученого секретаря Президиума НАНБ О.И. Семенков.
Совещание в ИПС РАН прошло 10-11 июня 1998 г. Были согласованы не только технические возможности предприятий, но и возможный состав исполнителей со стороны Беларуси и России.
12 июня 1998 г. три организации (НАН Беларуси, ООО «Суперкомпьютерные системы» и ИПС РАН) подписали договор о начале реализации совместного проекта по созданию ряда отечественных суперкомпьютеров.
|
|
|



Договор о совместной деятельности
В течение 1998 г. шла организационная работа (например, с октября 1998 г. вместо ИТК НАНБ головным от Беларуси стало НПО «Кибернетика» НАНБ во главе с академиком В.С. Танаевым). ООО «Суперкомпьютерные системы» и ИПС РАН подготовило описание программы СКИБР. [1] Было определено, что Целью Проекта будет решение следующих основных задач:
- обеспечение возможности технологического прорыва и создания базы для интенсивного развития промышленности, науки и инфраструктуры путем удовлетворения насущных потребностей в технических средствах и технологиях высокопроизводительных вычислений важнейших субъектов деятельности в областях конструкторской деятельности, химической промышленности, фармацевтики, медицины, перспективных наукоемких разработок (термоядерный синтез, безопасные энергетические реакторы, ускорители), геологоразведки, национальной обороны, управления и др.;
- обеспечение национальной безопасности, как путем удовлетворения потребностей этой области в суперкомпьютерных вычислениях с использованием отечественных вычислительных средств, так и путем обеспечения независимости от монополизма американских, японских и европейских производителей суперкомпьютерной техники и ограничительной экспортной политики соответствующих государств;
- создание основы для дальнейшего развития отечественных перспективных разработок и наращивания отечественного потенциала в области производства высокопроизводительных средств вычислительной техники;
- переподготовка специалистов и обучение студентов новым технологиям программирования, привлечение их к выполнению программы, повышение престижа ВУЗов и предприятий.
В результате было решено перевести этот проект на уровень Союзного государства России и Беларуси. Это было продиктовано не только финансовыми возможностями участников проекта, но и значимостью его результатов для научно-технического развития двух государств.
Поскольку уровень утверждения программы поднялся до государственного, то из-за сохранения советской ментальности у руководителей большинства ведомств и учреждений было принято решение сделать со стороны Беларуси головным предприятием НИО «Кибернетика» НАНБ, а со стороны России – ИПС РАН. Наше предприятие ООО «Суперкомпьютерные системы» ради достижения общей цели из главных инициаторов и разработчиков ушло на второй план и стало простым соисполнителем. Эта та цена, которую мы заплатили, чтобы проект был реализован. И это стало причиной нашего забвения и отстранения от принятия стратегических решений по развитию проекта. Но тогда мы об этом не думали.
Для утверждения предложенного нами проекта была разработана Совместна программа Союзного государства "Разработка и освоение в серийном производстве семейства моделей высокопроизводительных вычислительных систем с параллельной архитектурой (суперкомпьютеров) и создание прикладных систем на их основе"(Шифр «СКИФ»)[2], разработана «Концепция создания моделей семейства суперкомпьютеров» [3], общее техническое задание на «Модели первого ряда семейства суперкомпьютеров» [4] и т.д.
Распределения производственных функций внутри Программы сложилось почти естественно и опиралось на производственный опыт еще Советского Союза: Беларусь обеспечивала производство процессоров и компьютеров (Унитарное предприятие «НИИЭВМ» - производство вычислительных комплексов, УП «Белмикросистемы» - производство процессоров), а Россия — разработку процессоров и системного программного обеспечения. Это было самое эффективное разделение труда на тот период.
Когда определились все главные исполнители и потребители, когда была проработана концепция будущего семейства суперкомпьютеров, согласованы с потребителями их параметры, мы вышли с предложением в Исполком Союза Беларуси и России (СБР) об утверждении программы по их производству.
Процесс согласование и утверждения этой программы шел целый год и был высшим бюрократически пилотажем. Перед утверждением на Исполкоме Союзного государства этой программы нужно было пройти ее согласование во всех профильных ведомствах и министерствах России и Беларуси. Это были листы согласований, за каждым из которых виделись заинтересованные организации. Так, чтобы получить согласование одного из министерств, пришлось в программу включить ОАО «НИЦЭВТ» (г. Москва) и другие российские организации.
|
|


Листы согласования от России
|
|


Листы согласования от Беларуси
В конце 1999 г. Программа была утверждена как союзный проект. Его поддержали оба руководителя наших государств. Решение о его старте подписал будущий президент России Владимир Путин.

|
| |
Постановление №43 от 22.11.1999 г
Исполнительного комитета Союза Беларуси и России
Следует отметить особое значение в утверждении проекта руководителя аппарата Исполкома Союза Белоруссии и России В.Н. Степанова, Постоянного комитета Союзного Государства П.П. Бородина, а также ответственных сотрудников Исполкома, а затем и Постоянного комитета А.А. Бевзо и М.С. Осипова.
Научным руководителем Программы от РФ слал профессор Альфред Карлович Айламазян, исполнительным директор Программы от РФ - д. ф.-м. н. Сергей Михайлович Абрамов
Научным руководителем Программы от РБ стал академик Вячеслав Сергеевич Танаев, а исполнительным директором Программы от РБ - Николай Николаевич Парамонов.
Так с 2000 г. стартовал этот проект.
ОБ ИСТОРИИ ТЕХНОЛОГИЙ ПРОЕКТА «СКИФ».
I.ОДНОРОДНО-ВЫЧИСЛИТЕЛЬНАЯ СРЕДА (ОВС)
В середине 60-х г. в Новосибирском Академгородке сформировалась научная школа по реконфигурируемым вычислениям под руководством чл.-корр. АН ССР Евреинова. В 70-х, 80-х в СССР активно шли научно-исследовательские работы по этому перспективному направлению. Ежегодно проходили всесоюзные конференции и школы-семинары по реконфигурируемым вычислениям. Был выпущен 5-томник научных трудов под общим заглавием «Параллельная обработка информации».
В 70-х г.г. в НИИ-17 (теперь НПО «Вега») в рамках проекта «Аэлита» под руководством Главного конструктора В.И. Геворкяна был создан макет первого в мире комплекса с реконфигурируемой структурой.
Затем работы были переведены (вместе с коллективом разработчиков) в НПО «Астрофизика», где в конце 80-х годов под руководством Главного конструктора М.Богачева был создан прототип вычислительного комплекса с реконфигурируемой структурой, который использовался как система управления лазерным оружием в рамках работ по стратегической оборонной инициативе.
В начале 90-х годов разработчиками этой технологии было создано ЗАО «Мульткон», в рамка которого по заказу Министерства науки и при финансовом участии немецких фирм «Mir Gmbh» и «Rein Ceightungh» были разработаны новые процессоры и выпущен в 1993 г первый в мире персональный суперкомпьютер с реконфигурируемой архитектурой. Это компьютер демонстрировался на международных выставках "Информатика-93", "Связь-93" в Москве, "SYSTEM-93" в Мюнхене и "CeBit-94" в Ганновере и на выставке новейших российских технологий "Партнер-Россия" в Берлине в 1995г. и в Риме в 1996г. Он был разработан на процессорах, выпущенных на НПО "Интеграл" (Беларусь) еще на технологии 2,5 мкм, с тактовой частотой 5 МГц. Он состоял из 32-х одинаковых плат, на которых размещались одинаковых вычислительных элементов, соединенных в регулярную структуру. По габаритам он быль чуть больше обыкновенного персонального компьютера. Потреблял 300 Вт и имел производительность 10 миллиардов операций в секунду.
Хочу подчеркнуть: технология 2,5 мкм, тактовая частота 5 МГц, потребляемая мощность 300 Вт, производительность 10 миллиардов операций в секунду, размер BigTower, 1993 г.

Внешний вид "Мультикон" в сравнении с персоналным компьютером
|
|


Устройство "Мультикон"

Вычислительная плата "Мультикон"
Суперкомпьютер "Мультикон" получил высокую оценку, как российских специалистов, так и зарубежных, в частности, положительную аналитическая оценку независимой экспертизы из лаборатории параллельных систем университета г. Кобленца (Германия).
С конца 1997 г. работы по развитию этого направления уже шли в ООО «Суперкомпьютерные системы». Прототипом разрабатываемого в ООО «Суперкомпьютерные системы» Реконфигурируемого Вычислительного Модуля (РВМ) послужил именно это первый в мире персональный суперкомпьютер "Мультикон" с реконфигурируемой архитектурой.
Архитектура ОВС
Согласно определению однородные вычислительные среды (ОВС) представляют собой множество простейших процессоров, связанных между собой регулярным образом.
Архитектура ОВС позволяет использовать естественный параллелизм решаемой задачи вплоть до битового уровня, то есть уровня структуры обрабатываемых данных. ОВС также предоставляет возможность многоконвейерной обработки несвязанных потоков данных. Основой ОВС являются последовательные процессоры типа "супер-RISC" с минимальным набором команд, изначально ориентированные на мультиконвейерную обработку. Матрица ОВС может быть поделена на блоки, физически удаленные и связанные оптическими линиями связи. По периферии могут подключаться внешние устройства. Существуют несколько способов подключения:
- Подключение к стандартной шине (PCI,VME и т.д.);
- подключение через стандартные адаптеры ;
- подключение непосредственно к процессорным элементам (ПЭ) с учетом согласования уровней сигналов.
Таким образом, из стандартных матриц ПЭ легко может быть собрана система - модуль или кластер РВМ (реконфигурируемой вычислительной машины) - наиболее эффективная для решения конкретной задачи, например, система управления сложными объектами. Размер матрицы может легко быть изменен. Неисправные процессоры исключаются из работы, что начинает сказываться на производительности системы только при массовом выходе их из строя. Матрица ПЭ работает по принципу конвейера, который с каждым тактом загружается информацией на одном конце, а на другом конце производится разгрузка полученных результатов обработки информации. Структура обеспечивает параллельную организацию множества конвейеров. Все операции в конвейере выполняются при непрерывном продвижении информации. Так как при этом не требуется запоминать промежуточные результаты, то сильно уменьшается потребность в оперативной памяти.
Фактически, при выполнении конкретного вычислительного процесса, на ОВС программным путем организуется структура спецпроцессора, оптимально реализующего решаемую задачу. Одновременно могут выполняться несколько процессов, причем механизм перезагрузки сегментов ОВС позволяет осуществлять это без остановки выполнения еще незавершенных задач. В качестве аналога ОВС могут выступать систолические структуры. Но, реализуя все возможности систолических структур, ОВС обладает значительно большей гибкостью и перестраиваемостью. Последнее свойство и дало новое название РВМ (реконфигурируемые вычислительные модули) системам, использующих парадигму реконфигурируемых вычислений и построенных по принципу ОВС.
Кроме того, ОВС можно считать аналогом так называемых Very Big Instruction процессоров, так как ОВС как бы поглощает сверхдлинную команду, реализующую тот или иной алгоритм, и выполняет ее для заданного набора данных. И это при том, что ОВС сохраняет все преимущества RISC архитектур:
- эффективное использование всех предоставляемых вычислительных мощностей;
- относительную простоту изготовления;
- низкую себестоимость процессоров.
ОВС (или РВМ, построенная по принципу ОВС) обладает полной аппаратной и программной масштабируемостью, что позволяет строить на базе матрицы ПЭ вычислительные системы с весьма большим быстродействием. Последнее преимущество по своей значимости необходимо поставить на одно из первых мест, поскольку на текущий момент ни один из существующих суперкомпьютеров не предлагает реальной возможности программного и аппаратного масштабирования одновременно: либо обеспечивается удобное наращивание аппаратных средств вычисления, но при этом проявляется полная зависимость программных средств от текущей архитектуры (мультитранспьютеры); либо программные средства гибко реагируют на изменение количества вычислительных единиц, но рост числа процессоров строго ограничивается (компьютеры серии Gray); либо делается попытка обеспечения роста вычислительных мощностей без внесения существенных изменений в программные продукты, но в результате получают системы с весьма неутешительным ростом производительности.
Производительность ОВС, теоретически, растет линейно с увеличением рабочей частоты поля и площадью вычислительной матрицы и не требует от пользователя внесения изменений в программное обеспечение. При этом ОВС позволяет создавать системы с высоким уровнем надежности и отказоустойчивости и весьма успешно справляется с так называемыми задачами "реального времени".
Кроме того, ОВС, благодаря удачному объединению вычислительной и коммутационной матриц, позволяет эффективно моделировать нейрокомпьютеры.
За счет оригинальных технических решений достигаются наилучшие удельные объемные, массогабаритные и стоимостные характеристики изделий в части производительности и энергопотребления, в частности:
- минимальная потребляемая мощность на единицу объема;
- минимальные габариты и вес;
- наилучшее соотношение стоимость/производительность;
- максимальная производительность на единицу объема..
Особенности программирования на ОВС
Основную особенность программирования на ОВС определяет принцип статического программирования—программа для ОВС раскладывается по полю процессорных элементов, создавая как бы спецвычислитель для конкретного алгоритма. В течение выполнения программы данные "протекают" через запрограммированный участок, преобразовываясь в соответствии с регистрами команд процессорных элементов. Необходимо отметить, что ОВС способна осуществлять весьма разнообразные операции над потоком данных—задерживать относительно друг друга, переставлять элементы как в рамках одного потока, так и между потоками, переключать входные и выходные каналы данных, осуществлять выборку по заданному условию и множество других полезных операций. Одновременно с операциями чисто коммутационного характера ОВС может осуществлять арифметические, логические и прочие преобразования данных, а темпы движения данных и темпы вычислений всегда соответствуют друг другу. Вообще статическое программирование при наличии необходимых ресурсов обеспечивает наиболее высокий уровень распараллеливания задачи.
Благодаря простоте наращивания поля ОВС модель статического программирования изначально позволяет достигать наилучшей оптимизации решаемой задачи по скорости. Перепрограммирование части поля ОВС имеет смысл лишь для задач, разбиваемых на непересекающиеся по времени подзадачи, либо в случае выполнения нескольких полностью независимых процессов одновременно, поэтому статическое программирование стало основным инструментом для ОВС. Хотя следует отметить, что в ОВС предусмотрена возможность перепрограммирования по ходу выполнения задачи. На поле ОВС одновременно могут выполняться множество независимых процессов. При этом для их совместной работы не требуется надзор операционной системы.
Одной из наиболее серьезных проблем современных компьютеров является шина данных, а точнее, ее пропускная способность. Соотношение процессор—шина данных всегда выигрывает процессор—его быстродействие, как правило, значительно выше пропускной способности шины. Дополнительно к шине прикреплено несколько внешних устройств, таких как ОЗУ, сетевые адаптеры, возможно видеокарты и множество других средств. А если к компьютеру подсоединили источник большого непрерывного потока данных, например, цифровую видеокамеру или радар, то без сложных специальных решений не обойтись. В настоящем проекте данная проблема решается при помощи ОВС—поля процессорных элементов с RISC набором команд.
В качестве одного из вариантов определения поле ОВС можно охарактеризовать как "интеллектуальную шину". Это означает, что все поле процессорных элементов может одновременно передавать данные и при необходимости обрабатывать их. Вследствие того, что каждый процессорный элемент обрабатывает за один такт один бит информации, получаем архитектуру с полным параллелизмом, настраиваемую на произвольную разрядность и структуру данных. Процессорные элементы, объединенные в регулярную решетку, позволяют организовать большое количество конвейеров, действующих параллельно и, если необходимо, независимо. Перед началом решения задачи программа раскладывается по полю процессорных элементов.
ЭТОТ ПРОЦЕСС АНАЛОГИЧЕН СОЗДАНИЮ СПЕЦВЫЧИСЛИТЕЛЯ ДЛЯ ЗАДАННОГО АЛГОРИТМА. ПРИЧЕМ НА ПОЛЕ ОВС МОЖЕТ РАБОТАТЬ НЕСКОЛЬКО НЕЗАВИСИМЫХ "СПЕЦВЫЧИСЛИТЕЛЕЙ", А ИХ КОЛИЧЕСТВО ЛИМИТИРУЕТСЯ ЛИШЬ РАЗМЕРАМИ ПОЛЯ ПРОЦЕССОРНЫХ ЭЛЕМЕНТОВ.
Программирование на ОВС можно разделить на три уровня абстракции. Первый уровень—это язык Ассемблера. Второй уровень основан на модели ярусно-параллельного графа, а третий уровень предполагает возможность программировать на языках высокого уровня. Такое разделение позволяет создавать реально масштабируемое программное обеспечение для ОВС. Иначе говоря, предлагаемая концепция построения программ обеспечивает возможность изменять ресурсы вычислительной среды без изменения уже созданного программного обеспечения.
Варианты реализации ОВС
За период с 1992 по 2000 г. были разработаны три варианта архитектуры модуля РВМ.
Первый вариант, разработанный в 1993 г., "Мультикон" был самый простой. Процессор ОВС выполнял 6 арифметико-логических и две управляющих операции, кроме того, одновременно мог передавать информацию без обработки от одного соседнего процессора другому соседнему. Кроме процессора ОВС был еще разработан процессор однородной запоминающей среды (ОЗС), выполнявший операции динамического хранения и управляемой коммутации входных данных. Платы ОВС и ОЗС составляли матрицу процессоров ОВЗС. Недостатками данной архитектуры являются трудности при работе с плавающей запятой (ПЗ), неэффективное использование ОЗС, достаточно тяжелая реализация «длинных» операций (типа умножение), использование большого числа процессоров только для передачи данных.
Второй вариант - «МиниТера1» был разработан в 1997-1998 г. В систему команд процессора ОВС дополнительно была введена операция потокового целочисленного умножения 8-разрядного числа на число произвольной длины. Кроме того, в рамках одной СБИС были объединены процессоры ОВС и ОЗС, причем на 4 процессора ОВС приходился один процессор ОЗС. Матрица процессоров ОВЗС состояла из таких СБИС. Недостатками данной архитектуры была невозможность использовать ресурсы процессора ОЗС для выполнения команд процессором ОВС, а также частые конфликты при использовании процессорами ОВС из одной «четверки» общего процессора ОЗС, трудности при работе с ПЗ.
Третий вариант - «МиниТера2», который был реализован в проекте «СКИФ», начал разрабатываться в конце 1999 г. Этот вариант воплотил в себе решения, предложенные после анализа алгоритмов из различных областей приложений. В этом варианте были объединены процессоры ОВС и ОЗС, причем система команд процессора была увеличена как с целью повышения эффективности использования "кремния", так и с целью упрощения высокоуровневого программирования. Аппаратные ресурсы процессора ОЗС стали доступными при выполнении арифметико-логических операций, что позволило эффективнее реализовать ряд операций, в том числе и операции с плавающей запятой. Кроме того, новый процессор ОВС мог одновременно передавать информацию без обработки от трех соседних процессоров трем другим соседним. Еще тремя важными отличиями были:
- возможность вводить программу одновременно с обработкой данных предыдущей программой за счет введения «теневой» памяти. Это особенно важно для совместной работы с кластером.
- Возможность быстрого (за один такт) переключения с предыдущей программы на вновь введенную и обратно. Этот и предыдущий пункты являются основой оперативной реконфигурируемости модуля РВМ.
- Возможность выгрузки внутреннего состояния всех процессоров СБИС, что значительно облегчает отладку.
Как видим, развитие шло в направлении усложнения системы команд с целью расширения области применения (в частности введена поддержка операций с плавающей точкой), повышения пропускной способности каналов передачи данных и уменьшения времени реконфигурации модуля за счет введения теневой памяти.
II. МУЛЬТИПРОЦЕССОР С ДИНАМИЧЕСКОЙ АРХИТЕКТУРОЙ (МДА)
История развития кластерного уровня гибридной вычислительной системы, с которым связаны разработки предприятия «Суперкомпьютерные системы», восходит к работам проф. В.А. Торгашева по организации параллельных вычислительных процессов и их программирования в мультипроцессорах с динамической архитектурой (МДА), основанных на модели вычислений, именуемой «динамические автоматные сети» (ДАС).
Более 20 лет назад В.А. Торгашевым была выдвинута идея рекурсивных вычислительных машин, анализ недостатков которых привел к созданию теории динамических автоматных сетей (ДАС), которая и была положена в основу МДА[5]. МДА - это мультипроцессор, представляющий собой множество вычислительных модулей, соединенных в сеть. Каждый из этих модулей представляет собой в общем случае мультипроцессорную систему, в которой каждый процессор имеет свою специализированную функцию. Все процессоры в вычислительном модуле работают параллельно, асинхронно и независимо, а взаимодействие между ними осуществляется при помощи системы аппаратно поддерживаемых очередей, размещаемых в локальной памяти процессоров.
В 1986-1988 гг. СПИИ РАН совместно с НИЦЭВТ был создан образец МДА ЕС-2704 на элементной базе ЕС ЭВМ, который прошел испытания, подтвердившие основные свойства МДА. Он представлял из себя мультипроцессор, состоящий из 24-х модулей и занимавший одну стандартную стойку ЕС ЭВМ, с быстродействием около 100 млн. операций в сек.

В 1992 г. В.У. Плюснин (ОАО «НИЦЭВТ»), В.Ю. Татур, В.Г. Страхов и др. создали ЗАО «РеСКо» (Рекурсивные СуперКомпьютеры). В 1993 г. я возглавил эту компанию и осуществлял финансирование всех работ из собственных средств, которые были заработаны ранее в различных коммерческих сделках. В этом же 1993 году (с 30.08 по 04.09) ЗАО «РеСКо» организовало Вторую Международную конференцию по параллельным вычислениям «Parallel Computing Technologies”,опубликовало 3  тома материалов этой конференции а так же выпустило МДА на передовой (на то время) элементной базе (микропроцессорах серии TMS320С30 фирмы Texas Instruments). МДА на базе TMS320С30 (RS30) был 6-ти процессорным с пиковой производительностью около 180 миллионов операций в секунду ( примерно 100 IBM PC AT 386 ) и размещался в корпусе РС (платформа IBM PC AT). Он имел те же основные свойства, что и МДА ЕС-2704 - быстродействие компьютера росло пропорционально количеству модулей, задача автоматически распараллеливалась на имеющиеся вычислительные ресурсы, при этом выход из строя одного из процессоров не останавливал вычисления, а лишь приводил к замедлению скорости вычислений. Для описания задач был разработан язык программирования высокого уровня (И.В.Царев), создана уникальная графическая система (В.М. Дегтярев), позволяющая до 5 порядков уменьшать оперативную память для описания изображения, что позволило еще в 1993 г. создать новый класс компьютерных игр - динамические стереоигры, в частности, первую стереоигру, в которой в реальном режиме времени происходили вычисления каждого последующего игрового события для нескольких игроков, что и было продемонстрирована мною на международных выставках "Информатика-93" и "Информатика-94". Информация об этой разработке была помещена во многих изданиях. Реклама об этой разработке размещалась в 1993-1994 г. в различных изданиях: «Московский обозреватель», New Times Internetional, Коммерсантъ Daily, газета “Воздушный транспорт», The New York Times,
тома материалов этой конференции а так же выпустило МДА на передовой (на то время) элементной базе (микропроцессорах серии TMS320С30 фирмы Texas Instruments). МДА на базе TMS320С30 (RS30) был 6-ти процессорным с пиковой производительностью около 180 миллионов операций в секунду ( примерно 100 IBM PC AT 386 ) и размещался в корпусе РС (платформа IBM PC AT). Он имел те же основные свойства, что и МДА ЕС-2704 - быстродействие компьютера росло пропорционально количеству модулей, задача автоматически распараллеливалась на имеющиеся вычислительные ресурсы, при этом выход из строя одного из процессоров не останавливал вычисления, а лишь приводил к замедлению скорости вычислений. Для описания задач был разработан язык программирования высокого уровня (И.В.Царев), создана уникальная графическая система (В.М. Дегтярев), позволяющая до 5 порядков уменьшать оперативную память для описания изображения, что позволило еще в 1993 г. создать новый класс компьютерных игр - динамические стереоигры, в частности, первую стереоигру, в которой в реальном режиме времени происходили вычисления каждого последующего игрового события для нескольких игроков, что и было продемонстрирована мною на международных выставках "Информатика-93" и "Информатика-94". Информация об этой разработке была помещена во многих изданиях. Реклама об этой разработке размещалась в 1993-1994 г. в различных изданиях: «Московский обозреватель», New Times Internetional, Коммерсантъ Daily, газета “Воздушный транспорт», The New York Times,

New Times Internetional
Публиковались статья в газетах «Народная газета», «Деловой мир», «Не может быть»[6], «Красная звезда», «Тверская, 13».

|
| |
«Деловой мир»
В международном журнале «Megapolis»[7], в книгах.

|
| |
В книге на развороте
1992-1994 гг были годами бешенной инфляции. 1992- 2500%, 1993-840%, 1994- 200%. В этих условиях очень сложно было даже сохранить заработанные средства, не говоря уж о том, чтобы регулярно их инвестировать. Но даже в этих условиях ряд финансовых операций, которые я провел, позволили относительно устойчиво вести финансирование работ ЗАО «РеСКо» до середины 1994 г. Потом работы были остановлены, фирма оказалась на грани банкротства. Но реклама произвела эффект. Нашими технологиями заинтересовалась американская компания «Nick & C Corporation», которая работала в области авиастроения. Так в начале 1995 г. мы получили заказ от этой компании на создание новой графической станции для проектирования некоторых узлов самолетов.
В 1992 - 1995 г.г. фирмой «РеСКо» были созданы несколько вариаций МДА на базе микропроцессоров серии TMS320С30 и TMS320С40 фирмы Texas Instruments. МДА на базе TMS320С30 (RS30) был 6-ти процессорным с пиковой производительностью около 180 миллионов операций в секунду и размещался в корпусе РС. МДА на базе TMS320С30 демонстрировался на различных компьютерных выставках и получил широкое освещение в прессе. В 1995 г. был создан МДА на базе TMS320С40 (RS40), который обладал более высокими характеристиками. Для этого компьютера был разработан 3-х мерный САПР (В.М. Дегтярев) для расчета некоторых узлов самолетов.

|
| |
В 1995-1996 гг. ЗАО «РеСКо» финансировало создание Т-системы, которая разрабатывалась С.А Абрамовым и А.И. Адамовичем в ИПС РАН, в частности, работы по реализации системы автоматического динамического распараллеливания программ для архитектуры «однородный мультипроцессор, построенный на основе рабочих станций, функционирующий под управлением ОС семейства UNIX (OC Linux) и объединенных локальной сетью с использованием сетевых протоколов семейства TCP/IP». Тогда из-за отсутствия финансирования проект создания Т-системы в ИПС РАН был на гране развала. Наше финансирование сохранило этот проект. Потом разработку Т-системы уже поддержал «Российский фонд фундаментальных исследований» и к 1998 г. о Т-системе можно было говорить, как об основе будущего проекта «СКИФ». [8]
III. Т-СИСТЕМА
Технологические сложности, возникшие в России в середине 90-х годов, и отсутствие на внешнем рынке подходящей элементной базы, не позволили реализовать вариант МДА с полностью автоматическим динамическим распараллеливанием программ. Важнейшим шагом в этом направлении стали работы в ИПС РАН проф. С.М. Абрамова, который в конце 80-х годов сотрудничал с В.А. Торгашевым. С.М. Абрамовым была предложена и под его руководством разработана система поддержки параллельных вычислений—Т-система, реализующая автоматическое динамическое распараллеливание программ.
Именно Т-система легла в основу проекта "СКИФ" кластерного уровня — тесно связанной сети (кластер) вычислительных узлов, работающих под управлением ОС Linux—одного из клонов широко используемой многопользовательской универсальной операционной системы UNIX. Для организации параллельного выполнения прикладных задач на данном уровне, кроме Т-системы, использовались классические системы поддержки параллельных вычислений, обеспечивающие эффективное распараллеливание прикладных задач различных классов (как правило—задач с явным параллелизмом): MPI, PVM, Norma, DVM и др.
В варианте МиниТеры, реализуемой по проекту СКИФ, Т-система обеспечивала автоматическое динамическое распараллеливание программ и, таким образом, достигалось освобождение программиста от большинства аспектов разработки параллельных программ, свойственных различным системам ручного статического распараллеливания:
- обнаружение готовых к выполнению фрагментов задачи (процессов);
- их распределение по процессорам;
- их синхронизацию по данным.
Все эти (и другие) операции выполнялись в Т-системе автоматически и в динамике (во время выполнения задачи). Тем самым достигались более низкие затраты на разработку параллельных программ и более высокая их надежность.
По сравнению с использованием распараллеливающих компиляторов, Т-система обеспечивала более глубокий уровень параллелизма во время выполнения программы и более полное использование вычислительных ресурсов мультипроцессоров. Это связано с принципиальными алгоритмическими трудностями (алгоритмически неразрешимыми проблемами), не позволяющими во время компиляции (в статике) выполнить полный точный анализ и предсказать последующее поведение программы во время счета.
Кроме указанных выше принципиальных преимуществ Т-системы перед известными тогда методами организации параллельного счета, в реализации Т-системы имелся ряд технологических находок, не имеющих аналогов в мире, в частности:
- реализация понятия "неготовое значение" и поддержка корректного выполнения некоторых операций над неготовыми значениями. Тем самым поддерживается возможность выполнение счета в некотором процессе-потребителе в условиях, когда часть из обрабатываемых им значений еще не готова—не вычислена в соответствующем процессе-поставщике. Данное техническое решение обеспечивает обнаружение более глубокого параллелизма в программе;
- оригинальный алгоритм динамического автоматического распределения процессов по процессорам. Данный алгоритм учитывает особенности неоднородных распределенных вычислительных сетей. По сравнению с известными алгоритмами динамического автоматического распределения процессов по процессорам (например, с диффузионным алгоритмом и его модификациями), алгоритм Т-системы имеет существенно более низкий трафик межпроцессорных передач. Тем самым, Т-система обеспечивает снижение накладных расходов на организацию параллельного счета и предъявляет менее жесткие требования к пропускной способности аппаратуры объединения процессорных элементов в кластер.
ИТОГИ
1. ПРОЕКТ «СКИФ»
Уже в 2001 г. УП «НИИЭВМ» и ИПС РАН создали два опытных образца суперкомпьютеров производительностью 20 миллиардов операций в секунду для отладки программного обеспечения. Об этом я написал в статье в НГ-наука [9].

Опытный образец кластера
ООО «Суперкомпьютерные системы» за 3 года разработало архитектуру микропроцессора, системное программное обеспечение, эмулятор ОВС и прикладные задачи для демонстрации возможностей ОВС.
Для того чтобы успеть отладить программное обеспечение, в 2002 г. на основе технологии Xilinx был создан лабораторный образец вычислительной системы (эмулятор ОВС), на котором до выпуска процессоров в 2003 г. программно создавалась вычислительная среда «МиниТера». На этом стенде было можно:
- отлаживать различные программы
- улучшать архитектуру и качество процессоров
- вести разработку и отлаживать следующие версии процессоров МиниТера

Плата лабораторного образца – эмулятора ОВС
Параллельно с проектом «СКИФ» ООО «Суперкомпьютерные системы» разработало и изготовило по заказу ОКБ «Электроавтоматика» (г. Санкт-Петербург) макет РВМ на основе Xilix для бортовой вычислительной машины (БВМ) пятого поколения.

Макет РВМ на основе Xilix для бортовой вычислительной машины (БВМ) пятого поколения
Но самое главное, совместно с УП «НИИЭВМ» и УП «Белмикросистемы» (Беларусь) к 2004 г. был изготовлен и протестирован опытный образец реконфигурируемого вычислительного модуля «МиниТера» с использованием процессоров, выпущенных по технологии 0,6 мкм.


Опытный образец реконфигурируемого вычислительного модуля «МиниТера»
В его создании принимали участие сотрудники ООО «Суперкомпьютерные системы»: Геворкян В.И., Бачериков Г.И., Яжук А.А., Афанасьев О.В., Майоров С.Н., Беленов А.В., Комаров А.В., Сидоров А.В., Шумилин С.С., Бачериков К.Г. и др.
К середине 2004 г. он был отлажен и объединен в гибридную установку с кластером. Были запущены несколько тестовых задач, которые продемонстрировали зависимость производительности от частоты и количества процессорных элементов, а также точность работы программного эмулятора.
На этом работы ООО «Суперкомпьютерные системы» в рамках проекта «СКИФ» были завершены.
Развитие проекта было направлено на сборку из иностранных комплектующих кластеров и развитие Т-системы.
В рамках проекта «СКИФ» были созданы сверхпроизводительный кластер «Скиф К-500», который в 2003 году занял 407-ю позицию в 22-й редакции рейтинга Тор500, и «Скиф К-1000».
Осенью 2004 г. кластер «Скиф К-1000» на базе 576 процессоров AMD Opteron был установлен в Минске. Пиковая производительность кластера составляла 2.5 терафлопа, реальная производительность на тесте Linpack - 2,032 терафлопа. Суперкомпьютер «Скиф К-1000» являлся в 2004 г. наиболее мощной из всех вычислительных систем, установленных на территориях России, СНГ и Восточной Европы, и входил в число 100 наиболее мощных компьютеров мира: «Скиф К-1000» занял 98-ю позицию в новой редакции мирового рейтинга суперкомпьютеров Top500, изданной 9 ноября 2004 года. На основе этого кластера в Минске был создан Республиканский cуперкомпьютерный центр. Кластер «Скиф К-1000» применялся для решения задач, требующих высокопроизводительных вычислений в наукоемких отраслях промышленности, биотехнологиях, медицине, генетике, геологоразведке, для контроля за окружающей средой, прогнозирования погоды и и т.д.
Вот не полный перечень использования суперкомпьютеров семейства СКИФ (включая СКИФ К-1000).
СПИСОК ПРИКЛАДНЫХ СИСТЕМ И ПРИМЕРОВ ПРИМЕНЕНИЯ
1. Прикладные системы собственной разработки
1.1 MultiGen @OpenTS (ЧелГУ)
Прогнозирование и проектирование в химии (лекарства и другие соединения)
- интенсивные квантовохимические расчеты для исследования органических соединений (синтез лекарств); создание параллельных версий программ MultiGen, BiS, DesPot и GAMESS (ЧелГУ, Университет Тюбингена, Германия)
- исследование перспективных органических парамагнетиков, а также материалов для создания молекулярных парамагнитных кристаллов (ЧелГУ, Новосибирский ИОХ СО РАН, Бременский университет, Германия)
- произведены расчеты люминесцентных характеристик ряда гетероциклов (ЧелГУ, ИОС УрО РАН г. Екатеринбург, Уральский политехнический институт)
1.2 НИИ мех. МГУ, @OpenTS
- Aэромеханика плохообтекаемых тел.
1.3 GDT Software Group, г. Тула, параллельная версия пакета Gas Dynamics Tool
1.4 ИПС РАН, @OpenTS, LANDSAT Image Classification
Обработка результатов ДЗЗ, эксперт на гиперспектральном снимке со спутника LANDSAT отмечает маленькие кусочки поверхностей как образцы: "это лиственный лес, это удачные всходы, это болото, это водоем ..." - до трех десятков категорий; система весь снимок расклассифицирует по данным категориям (какие-то пикселы в категорию "не распознано").
1.5 НИИ КС, @OpenTS, три системы связанные с обработкой результатов ДЗЗ
- Программная система формирования фокусированных радиолокационных изображений.
- Программная система моделирования широкополосных пространственно-временных радиолокационных сигналов.
- Программная система поточечной обработки цветных и полутоновых видео-данных космических систем дистанционного зондирования земли.
1.6 ИВВиИС: Система расчета химических реакторов
1.7 Гидрометеорология
- ИПС РАН, Росгидромет: Модель проф. В.М. Лосева и другие метеорологические модели.
- ОИПИ НАН Беларуси. Республиканский Гидрометеорологический центр (РГМЦ): модели регионального прогноза погоды на 48 часов, численные методы прогнозирования погоды
1.8 ИЦИИ ИПС РАН: три прикладные системы ИИ
- АКТИС: классификации текстов по заданным в процессе обучения классам (глубокий анализ текста, высокая релевантность)
- INEX: извлечение знаний из неструктурированных текстов на ЕЯ (заполнение заданной рел. БД)
- MIRACLE, @OpenTS: инструментальная система для проектирования интеллектуальных систем
1.9 Россия и Беларусь: использование семейства "СКИФ" в кардиологии
- ОИПИ НАН Беларуси, РНПЦ "Кардиология" и УП "НИИЭВМ": Аппаратно-программный кардиологический комплекс с использованием вычислительного модуля ОВС и кластера СКИФ. Клиническая апробация (завершена) аппаратно-программного кардиологического комплекса;
- ADEPT-C, ИВВиИС: кардиологическая экспертная система реального времени "ADEPT-C", решение о выдаче патента на изобретение No 2003102345/14(002527) от 29.01.2003 "Информационно-аналитическая система в области телемедицины"
1.10 ИТМО им. А.В. Лыкова НАН Беларуси
- Динамика лазерного факела у поверхности твердотельной мишени в воздухе
- Динамика интегральных по спектру компонент потока излучения лазерного факела
- Гиперзвуковое движение космического тела в плотных слоях атмосферы
- Удар астероида по поверхности Земли
- Численные модели реализующие методы молекулярной динамики для моделирования наноструктур, их алгоритмической и программной реализации
- Моделирование процессов лазерного спекания порошковых материалов (для медицинских изделий)
1.11 Белорусский государственный университет и Институт тепло- и массообмена НАН Беларуси
- программный комплекс расчета зонной структуры твердых тел;
- численное моделирование элементарных процессов радиационной газовой динамики
1.12 БГУ, геомеханические задачи
- Моделирование деформационных процессов на земной поверхности
- Моделирование устойчивости подземных сооружений
- Напряженно-деформированное состояние подработанной толщи
1.13 ОИПИ НАН Беларуси и НИП "Геоинформационные системы": Прогноз ветрового переноса загрязнений при лесном пожаре
- Программно-информационный комплекс оперативного прогноза ветрового переноса загрязнений при чрезвычайных ситуациях.
1.14 ОИПИ НАН Беларуси: Система идентификации личности по голосу
- АРМ обучения системы Реализация предлагаемой технологии в МВД Беларуси; система сбора, учета и поиска лиц по фонограммам их речи.
1.15 ОИПИ НАН Беларуси, Военная академия Республики Беларусь: Программа оптимизации назначения частот в группе РЭС
- оптимизация частотно-территориальных планов радиоэлектронных средств с учетом ЭМС.
1.16 Институт физики им. Б.И. Степанова НАН Беларуси
- ·Численные модели в области проектирования оптических и лазерных систем.
1.17 Институт математики Национальной академии наук Беларуси
- ·Численное моделирование и вычислительная математика
1.18 Институт прикладной физики НАН Беларуси
- Численные модели в области вычислительной диагностики
1.19 Институт молекулярной и атомной физики НАН Беларуси
- Моделирование спекания сферических порошков импульсным лазерным из-лучением
1.20 Комитет государственной безопасности Республики Беларусь
- Специальные математические задачи и алгоритмы
- Отработка технологий решения задач перебора большой размерности
1.21 Институт молекулярной и атомной физики НАН Беларуси
- Моделирование спекания сферических порошков импульсным лазерным из-лучением
1.22 ООО "Софтклуб"
- Банковские информационные системы
2. Использование готовых (импортных, коммерческих) пакетов инженерных расчетов
2.1 Тракторы "Беларусь"
- Моделирование остовов перспективных универсальных тракторов "Беларусь"
- НИРУП "Белавтотракторостроение": Расчетно-исследовательские работы по ГНТП "Белавтотракторостроение
2.2 БелАЗ
- Расчет несущих конструкций карьерных самосвалов БелАЗ и шахтных крепей
2.3 Почвообрабатывающие агрегаты
- Расчет динамических характеристик почвообрабатывающих агрегатов
- ОИПИ НАН Беларуси: Совместно с Промышленным институтом сельскохозяйственных машин (г. Познань, Польша) ведутся работы по разработке технологий удаленного проектирования объектов сельскохозяйственной техники на базе суперкомпьютеров "СКИФ"
- Белорусский институт механизации сельского хозяйства (БИМСХ): Конечно-элементные расчеты условий разрушения рабочих органов почвообрабатывающих агрегатов
2.4 МАЗ
- Для МАЗа моделируются столкновения транспортных средств с неподвижными препятствиями
2.5 Борисовский завод агрегатов Минпром РБ
- Расчет турбокомпрессоров для наддува дизельных двигателей
2.6 Белорусский национальный технический университет (БНТУ)
- Численное моделирование и CAD/CAE/CAM/PDM технологии, обучение
2.7 Борисовский завод агрегатов
- Проектирование, испытания и технологическая подготовка турбокомпрессоров для наддува дизельных двигателей Минского моторного завода
2.8 Гродненский завод "Белкард"
- Проектирование карданных валов
2.9 НИИ механики МГУ им. М.В. Ломоносова, с ИВТ РАН, МГТУ им. Н.Э. Баумана, НТЦ им. А.М. Люльки НПО "Сатурн" (коммерческие инж. пакеты)
- детонационное горение;
- система охлаждения реактора;
- распространение пламени форсунки камеры сгорания газотурбинной установки;
- оценка прочности авиационных газотурбинных двигателей.
В 2004 году программа «СКИФ» завершилась.
2.ПРОЕКТ «СКИФ-ГРИД»
Он пришел на смену проекту «СКИФ». Запущенная нами в 1998 г. программа продолжала свое развитие. В усеченном виде, но развитие, решая не все, но большое количество задач, которые были сформулированы в самом начале.
В рамках программы «СКИФ-ГРИД» была развернута экспериментальная ГРИД-сеть "СКИФ Полигон", объединяющая вычислительные ресурсы ряда суперкомпьютерных центров России и Беларуси. По сути, была заложена основа единой научно-исследовательской информационно-вычислительной сети Союзного государства. Таким образом, были созданы не только новейшие суперкомпьютеры, вычислительные машины и технологии, но и ГРИД-технологии - средства объединения суперкомпьютерных вычислительных центров, расположенных в разных регионах Союзного государства, в единую интегрированную систему суперкомпьютерных технологий.
Сегодня, как минимум, 75-80 процентов суперкомпьютеров отечественной разработки обеспечиваются суперЭВМ семейства «СКИФ» и установками с использованием технологических решений семейства СКИФ.
В рамках программ «СКИФ» и «СКИФ-ГРИД» были созданы четыре ряда (поколения) суперЭВМ. За всю историю существования списка лучших суперкомпьютеров мира в него входили восемь отечественных суперкомпьютеров. И шесть из них - именно компьютеры семейства «СКИФ»: «СКИФ К-500», «СКИФ К-1000», «СКИФ Cyberia», «СКИФ Урал», СКИФ МГУ «Чебышёв», «СКИФ-Аврора ЮУрГУ».
Так 19.03.2008 был запущен в МГУ «СКИФ», самый мощный в то время суперкомпьютер в СНГ. Компьютер занимал площадь в 96 квадратных метров и состоял из 1250 четырехъядерных процессоров. Емкость его оперативной памяти составляла 5,5 терабайт, а объем системы хранения данных - 60 терабайт. В качестве операционной системы для всех машины программы «СКИФ-ГРИД» был выбран ALT Linux 4.1, оптимизированный для кластерных систем.
Пиковая производительность компьютера СКИФ МГУ составляла 60 триллионов операций с плавающей запятой (терафлоп). Реальная производительность - 78,4 процента от пиковой. Это суперкомпьютер занимал 21-22 место мирового рейтинга суперкомпьютеров Top-500.
По предложению Виктора Садовничего этот суперкомпьютер назвали именем математика Пафнутия Чебышева, окончившего МГУ.
Первой задачей суперкомпьютера СКИФ МГУ «Чебышев» стали расчеты по созданию лекарства, которые позволят сократить срок их разработки с пятнадцати лет до трех.
Программа «СКИФ-ГРИД» завершилась разработкой революционного значения - суперкомпьютерами «СКИФ-Аврора», один из которых («СКИФ-Аврора ЮУрГУ») был установлен в Южно-Уральском государственном университете в Челябинске. Этот суперкомпьютер, по словам С.М. Абрамова, по семи технологическим показателям опережает сегодня все, что есть в мире, причем опережение очень существенное - от 1,5 до 5 раз по разным показателям.
Не обошел проект «СКИФ» и белорусские университеты. К примеру, в Гродненском государственном университете имени Янки Купалы в декабре 2009 года был установлен суперкомпьютер «СКИФ-К-1000.1» и открыт Гродненский региональный сегмент национальной ГРИД-сети Беларуси. Это был первый суперкомпьютер в Беларуси, установленный вне суперкомпьютерного центра НАН Беларуси. На этом суперкомпьютере, в частности, выполнялись расчеты технологии конструирования, модификации и проведение виртуальных испытаний для автомобилей "БелАЗ", а также оптимизация процессов расчета работы электро- и теплотехнического оборудования для "Гродноэнерго". Суперкомпьютер активно и по сей день используется для обучения студентов. В 2010 год были разработаны и прочитаны курсы "Параллельные вычисления и кластерные системы", "Компьютерное моделирование физических процессов", "Математические методы в физике". В 2011 году в университете начали работать по пяти научным темам в рамках государственных программ с использованием вычислительного кластера. Исследования ведутся совместно с такими вузами Беларуси, как БГУ, БГУИР, БНТУ.
Вот что про эту программу сказал П.А. Витязь, приложивший много усилий, чтобы «СКИФ» стартовал в 2000 г.: «Главная задача - это подготовка кадров, и очень удачно, что суперкомпьютеры прежде всего начали устанавливать в высших школах Беларуси и России. Вузам такие компьютеры нужны, чтобы разрабатывать новые программы для решения практических задач в области приборостроения, машиностроения, транспортной логистики. Внедрение суперкомпьютеров имеет важное значение с точки зрения создания единого технологического пространства в рамках Союзного государства».
3. МИССИЯ.
Большинство из технологий, разработанный в проекте «СКИФ» должны были стать основой проекта «МИССИЯ» (Мобильная Информационная Среда С Интеллектуальным Ядром). Российский суперкомпьютер мог стать на порядки меньше по размерам и весу. Это достигалось использованием технологии бескорпусной сборки, которую разработал и реализовал А.И. Таран.
Об этом проекте, опередившим время лет на 10 и не нашедшем поддержку, я расскажу в другой статье.
Ссылки
1. Белорусско-российская совместная программа по созданию высокопроизводительных вычислительных систем и приложений на их основе.
Описание Программы СКИБР в формате PDF (2042Кб) ![]()
2. Совместная белорусско-российская программа
"Разработка и освоение в серийном производстве семейства моделей высокопроизводительных вычислительных систем с параллельной архитектурой (суперкомпьютеров) и создание прикладных систем на их основе"
Программа в формате PDF (197Кб) ![]()
3.Концепция создания моделей семейства суперкомпьютеров
Концепция в формате PDF (640Кб) ![]()
4. Модели первого ряда семейства суперкомпьютеров.
Общее техническое задание в формате PDF (155Кб) ![]()
5. В. А. Торгашёв, И. В. Царёв, Средства организации параллельных вычислений и программирования в мультипроцессорах с динамической архитектурой
Полный текст доступен в формате PDF (261Кб) ![]()
6. Олег Поветкин, Электронный мозг? Это реальность!, «Не может быть», №2 (40)
Полный текст доступен в формате PDF (625Кб) ![]()
7.Вадим Татур, Быть ли нам компьютерной державой, Международный журнал «Megapolis» N1, 1995, стр. 29
Полный текст доступен в формате PDF (1190Кб) ![]()
8. С.М. Абрамов, А.И. Адамович Т-система—среда программирования с поддержкой автоматического динамического распараллеливания программ, 1998 г.
Полный текст доступен в формате PDF (207Кб) ![]()
9. В. Татур 20 миллиардов операций в секунду (Персональный суперкомпьютер постсоветской эпохи), НГ-наука, N2 от 21.02.01 г.
В.Ю. Татур, 15 лет проекту «СКИФ»: история и итоги // «Академия Тринитаризма», М.,
|
|